


Introduction
Oil and gas well data management system (A2) is one of the large-scale information systems of China National Petroleum Corporation (CNPC). Focusing on oil and gas production management, the A2 system fulfills collection, processing, statistics, calculation, submission and release of oil and gas well production data. To date, it manages production data of more than 360 thousand oil and gas wells in nearly 60 years, 60×108 records, 5 TB of structured data and four thousand concurrent users. Due to the huge amount of production data, high concurrency and technical limitations when building, the system adopts distributed deployment, i.e. 16 oil and gas field companies of CNPC each deploy a system to manage its oil and gas well production data, with a total of 16 databases. The A2 system adopts relational database and the data model is designed based on object-oriented model. The system mainly contains well information, production testing, oil and gas production, stimulation, oil recovery technology (well equipment), and oil and gas gathering (station) 6 kinds of data, 362 data tables and 9 512 data items. The A2 system has become a daily work platform for oil and gas production management of the field companies, achieving remarkable application effects.
Due to the huge amount of data, problems such as low query efficiency, isolated information among multiple databases and long time of manual data collection arise when all wells are integrally analyzed. (1) The query time exceeds 5 minutes in multi-table joint query when the number of data records is more than 10 million in relational database. (2) It takes a long time to collect data manually as information is separately stored in multiple databases which aren’t interconnected. When analyzing the production data of all oil and gas wells at the level of the CNPC, users have to repeatedly log in 16 systems to collect data, and then make statistics by hand, leading to repeated labor and low efficiency when analyzing all wells. Therefore, it is imperative to establish a system that allows query of the global oil and gas well production dynamics in real time, and can deeply discovery the potential useful information behind the data to support oil and gas production and research.
Chevron Company has used Hadoop technology to analyze seismic data to identify reservoir[3]. Meanwhile, the research and application of big data technology in oil and gas industry are also advancing in China. CNPC has established and put into application about 70 large scale information systems, and is promoting construction of smart oilfield[4]. Lu Shuaishuai built oil and gas drilling distributed data warehouse based on the big data platform[5]. Qu Haixu used big data technology to optimize oilfield production and operation[6]. Some progress has been made in the researches of intelligent drilling program optimization, logging curve generation and horizontal well geological modeling by combining big data with artificial intelligence[7,8,9,10].
To solve the problems such as low efficiency of database query and analysis, information isolation between multiple databases, and long time manual data collection in the process of global oil and gas well performance analysis at the level of CNPC, an information system that manages 360 thousand wells and provides instant query and multidimensional analysis functions by utilizing big data distributed storage and parallel computing technology, data warehouse modeling technology has been built.
1. Overall design
1.1. Architecture design
As the single machine deployment server is limited in processing capacity, the hardware resource of the single machine cannot meet the business need when the business grows to a certain extent[11,12,13]. Considering the huge amount and fast growth rate of oil and gas well production data, and computer performance expansion and cost, we chose Hadoop distributed file storage system and parallel computing framework as the basic architecture of the system. The Hadoop big data platform, distributed data warehouse (Hive), multidimensional analysis engine (Apache Kylin), and distributed real-time data warehouse (HBase) etc are used to construct the oil and gas production multidimensional analysis system (Fig. 1). Multi-dimensional analysis technology is adopted to ensure the second-level response and realize the centralized storage and management of the big data of more than 360 thousand oil and gas wells. Based on data analysis of all wells, the oil and gas production tracking, key oilfield production early warning, low production well and long shutdown well production analysis, classification of reservoir development law can be conducted at the level of CNPC. The process can be traced step by step from CNPC to company, oilfield, block and single well, meeting the requirements of knowing the oil and gas production performance of each unit in real time.
Fig. 1.
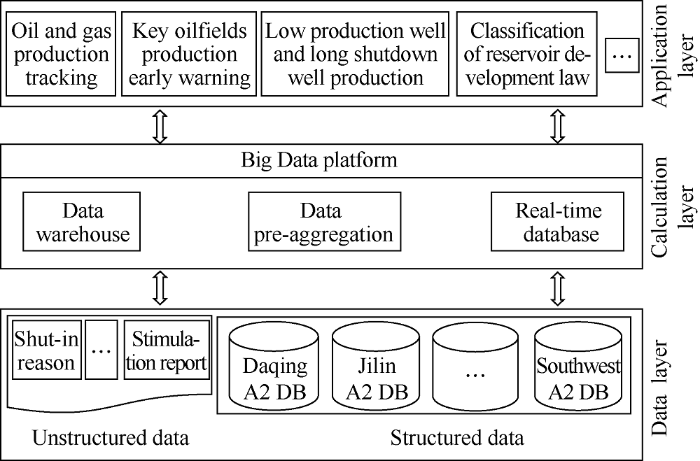
Fig. 1.
Multidimensional analysis architecture for oil and gas production.
1.2. Key technology
1.2.1. MapReduce parallel computation framework
MapReduce is a parallel computing framework suitable for parallel computing of large data set [14,15,16,17,18,19]. Its design idea is that a large computing task is divided into several small tasks, and then these small tasks are distributed to the working nodes for calculation; after all nodes complete its own computing task, the results of all nodes are aggregated to calculate the final result (Fig. 2).
Fig. 2.
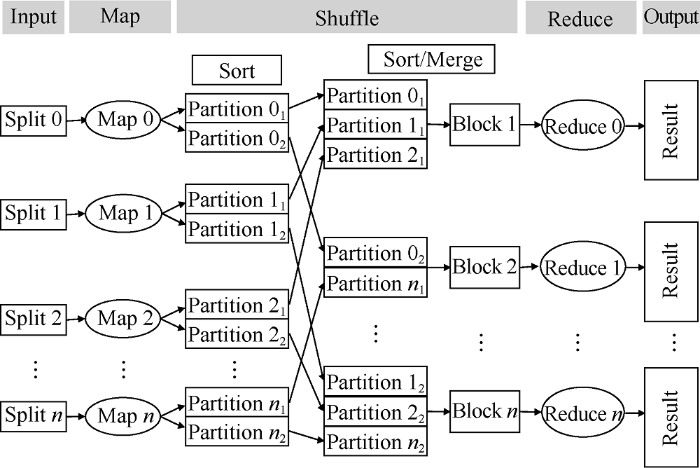
Fig. 2.
Parallel computing process.
1.2.2. Hive data warehouse
With instructions from the client, data stored in data warehouse can be retrieved through the console. Interfaces for applications to query data are also provided in Hive data warehouse.
The communication between the server and the client of Hive data warehouse is implemented based on the Thrift framework. The communication framework is also responsible for sending client SQL statements to the Driver parser and returning the results of the parser's processing.
1.2.3. Kylin multidimensional analysis engine
Apache Kylin is a distributed multidimensional analysis and computing engine with an open source.
Kylin is an application example of On-Line Analytical Processing technology on Hadoop, which can provide multidimensional analysis ability based on HDFS. With data processing and calculation ability reaching Petabyte level (1×250 bytes), it can query the information in the data warehouse in sub-second.
The multidimensional data is pre-computed and the result is stored, which will shorten the query response time at the expense of storage space[23]. The data is stored on HDFS instead of Kylin. The engine uses data in warehouse as input source. When a batch of data is input, all dimensions of the high-dimensional data will be computed and stored in the data cube of HBase database in the form of key-value pairs.
When the data is retrieved, the query service is converted into a scanning process on the HBase database, eliminating time-consuming computing tasks such as multi-table joins and aggregate operations, and enhancing query response speed.
1.2.4. HBase real-time query database
HBase is a non-relational database based on columnar storage, which solves the problem of delay when randomly reading and writing data on HDFS. With the high fault tolerance of HDFS, HBase is suitable for real-time query service of big data.
As a NoSQL database storage system, HBase can store structured and unstructured data, and provides a simple way to operate the database. The data in it comes in only one type, string, and the storage table in it can be designed large, with the number of rows and columns reaching more than 100 million and more than 1 million respectively[24].
2. Implementation
According to the overall design, the technical implementation mainly includes four steps: data warehouse modeling, data collection, multidimensional analysis and visualization.
2.1. Data warehouse modeling technique
The multidimensional analysis of big data in oil and gas production mainly includes oil and gas production tracking, early warning of key oilfield production, low production well and long shutdown well production analysis, and analysis of development law by reservoir type (Table 1). The data for each subject is multidimensional and needs to be analyzed from different perspectives. Taking oil field production analysis in the theme of dynamic development index tracking as an example, this paper introduces the modeling process of Hive data warehouse.
Table 1 Multidimensional analysis subject of oil and gas production.
| Subject | Target |
|---|---|
| Oil and gas production tracking | Track the production performance of the oilfield, analyze and predict the development situation of the company |
| Early warning of key oilfield production | Monitor the production performance of key oilfields, and make early warning and propose countermeasures timely |
| Low production well and long shutdown well production analysis | Focus on key issues in oilfield development and conduct research on key issues |
| Analysis of development law by reservoir type | Master the development laws of different types of reservoirs and implement reservoir management by type |
The production well data analysis mainly studies the production and operation of wells and blocks. The data covered includes the basic, production, status, stimulation, artificial lift, and shutdown information of wells, etc.
Multidimensional data analysis models mainly include fact tables and dimension tables. The fact table is in the center of the multidimensional model in the data warehouse structure and contains dimensions, foreign keys and metrics associated with the dimension table. A dimension table is a collection of attributes of a dimension, and a collection of attributes constitutes a dimension. The dimension is an important tool for users to analyze problems and also an important attribute. It is easier to obtain knowledge by changing the dimension to change the perspective of people's observation of data. Generally, for a simple data model, one fact table can represent one subject and correspond to multiple dimension tables.
The main dimensions of production data analysis of production wells include date, well type, drive type, production method, oil and gas type, well type, reservoir type, production unit, and organization, etc. (Table 2).
Table 2 Descriptions of dimension table of production well.
| Dimension | Description of dimension levels |
|---|---|
| Date | Year, quarter, month, ten days, day |
| Well purpose | Oil well, gas well |
| Drive type | Primary recovery, water flooding, chemical flooding, thermal recovery of heavy oil, etc. |
| Production method | Flowing, pumping unit, electric pump, screw pump, jet pump, and air lift, etc. |
| Oil and gas type | Thin oil, heavy oil, conventional natural gas, coal bed methane, shale gas |
| Well type | Vertical, horizontal |
| Reservoir type | Medium and high permeability sandstone, low permeability sandstone, conglomerate, and heavy oil, etc. |
| Production unit | Oilfield, reservoir, block, layer |
| Organization | Company, plant, mine and team |
The main production indexes related to the production data analysis of well include 105 in 6 categories, basic information, production, status, artificial lift, stimulation, and shutdown (Table 3).
Table 3 Fact table of production well.
| Subject | Fact table | |
|---|---|---|
| Data category | Indicators | |
| Data analysis of production well | Well information | Spud date, coordinate, and target formation, etc. |
| Production data | Production time, liquid production, oil production, water production, gas production, gas volume vented, verified liquid production, verified oil production, verified water production, verified gas production, water cut, and gas oil ratio, etc. | |
| Status data | Oil nozzle, electric pump current A, electric pump current B, electric pump current C, electric pump voltage, tubing pressure, casing pressure, back pressure, shutdown tubing pressure, and shutdown casing pressure, etc. | |
| Mechanical data | Pump efficiency, pump diameter, discharge capacity, stroke length, stroke frequency, revolutions, dynamic liquid level, static liquid level, theoretical discharge capacity, static pressure, and flowing pressure, etc. | |
| Stimulation data | Stimulation type, starting date, completion date, primary stimulation, secondary stimulation, oil production, oil production increment, etc. | |
| Shutdown data | Starting time, end time, shutdown type, gas production before shutdown, etc. | |
Multidimensional analysis of production well data is intensive computation. The advantage of star model is fast computation speed and simpler arrangement. Although it has the disadvantage of high data redundancy, this can be improved by MapReduce parallel computing technology. Therefore, star model is adopted in this study. The fact table in this model is connected to 9 dimension tables, with the fact table occupying the middle position (Fig. 3).
Fig. 3.
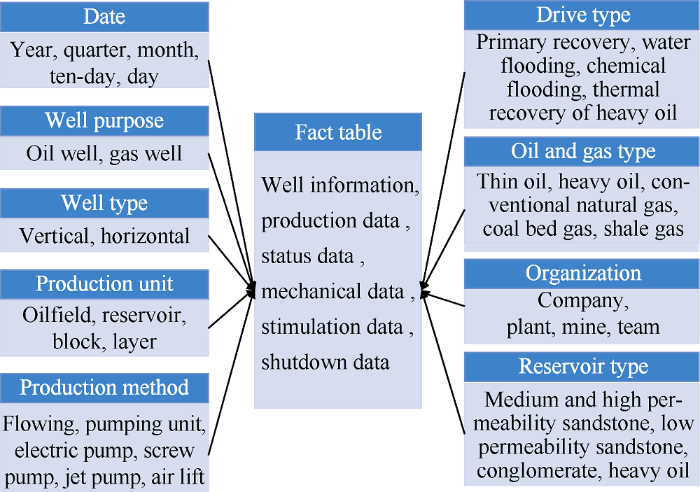
Fig. 3.
Analysis model of production well data.
2.2. Data collection technique
Oil and gas well production data from A2 database of 16 oil and gas field companies is load into Hive data warehouse. The data storage mode is transformed from transactional data format to subject-oriented format of oil and gas production (Fig. 4).
Fig. 4.
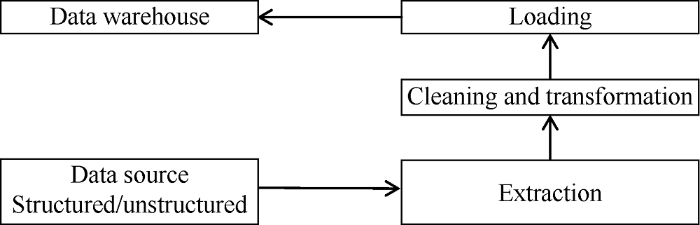
Fig. 4.
Data processing flow.
As the amount of data in the database of 16 oil and gas field companies is huge, when extracting data, a data cache should be set up to read the data from the database in one time. In the process of data extraction, the data is extracted to the temporary data storage area first, and then the data is transformed and cleaned.
The format and unit of data are standardized in the process of data transformation. The goal of cleaning is mainly to remove repeat information and correct the wrong data[25].
This job flow involved dimension tables of date, well class, drive type, production method, oil and gas type, well type, reservoir type, oil and gas unit, organization and the fact table of oil and gas production. Each dimension was defined, such as the time dimension. If the original data is a date field, it should be split, with a minimum unit of day, into year, quarter, month, ten days and day. The other dimensions follow the above rules for measurement unification, null value processing, and type conversion etc. The star model was formed through the cooperation of job flow and transformation flow.
2.3. Multidimensional analysis technique
Data pre-aggregation is mainly used for aggregating oil and gas production data in Hive data warehouse to meet the requirements of high response speed in OLAP query requests. Based on Kylin engine, this functional module is reengineered. Its internal functions are used through the interface provided by Kylin, and the system functions are extended on the basis of the original functions to meet the requirements of automatic operation, management, monitoring and alarming.
As an important object of OLAP data analysis, multidimensional data cube is a logical form of data storage. Quaternion (D, M, A, F) is used to define a multidimensional cube. The characteristics of the cube are described from different angles by different elements in the quaternion. The quaternion is defined as follows:
Constraint condition: ①$D\bigcap M=\varnothing $, the dimension set and measure set do not intersect; ②${{\forall }_{i,j}}$and$i\ne j$, $f\left( {{d}_{i}} \right)\bigcap f\left( {{d}_{j}} \right)=\varnothing $, sets of attributes of any two dimensions do not intersect.
The data analysis model of the multidimensional cube of production well can be defined as (Di, Mi, Ai, fi), where dimension set D includes 9 dimensions, date, well class, drive type, production method, oil and gas type, well type, reservoir type, production unit and organization. The measure set M includes well information, production data, status data, mechanical data, stimulation data, shutdown data and other production dynamic data. Attribute set A includes year, quarter, month, ten days, day, oil well, gas well, primary recovery, water flooding, chemical flooding, heavy oil recovery, flowing, pumping unit, electric pump, screw pump, jet pump, and air lift etc; F represents the hierarchy of dimensions.
Hive data warehouse is the data source of Kylin. After the production data is imported to Hive, a data model consistent with the data model in the data warehouse needs to be established in Kylin. The model includes a fact table and associated dimension tables, as well as the relationship between the fact table and dimension tables.
After the model is set, the cube engine is built. Data from Hive is inserted into a temporary table with many columns. As a large amount of oil and gas production data is stored in Hive, the way of partition and storage according to time is adopted to manage the data and enhance query efficiency. Cube's partition column, the same as Hive table's partition column, is time column. Cube calculation of Kylin is based on time, which enable the target data to be retrieved with the partition, rather than scanning all the data.
The data calculated by MapReduce is directly loaded into HBase and stored in key-value pair structure. Data can be directly read from HBase when retrieved.
2.4. Visualization technology
Visualization is an important way to directly display data relations. In this work, ASP.NET, Echarts3.0, WebGIS and other visual interface technologies are used to display the analysis results, to meet demand of knowing oil and gas production dynamics in real time and realize analysis of oil and gas well production big data.
3. Effect
In this study, applications such as oil and gas production tracking, early warning of key oilfield production, low production well and long shutdown well production analysis, development law by reservoir type were realized by using big data distributed storage and parallel computing, data warehouse modeling and multidimensional analysis technology. The production management of CNPC is more detailed with the basic unit of analysis refined from oilfield to single well (Table 4).
Table 4 Comparison of analysis methods and effects.
| Method | Basic unit | Data collection | Analysis method | Time |
|---|---|---|---|---|
| Conventional analysis | Oilfield, block | Manual operation | Manual operation | 1 d |
| Big data analysis | Well | Automatic operation | Automatic operation | 5 s |
Compared with the conventional manual analysis, the time of data preparation is dramatically shortened and the analysis efficiency is improved by using the common templates to draw multidimensional analysis diagrams.
Take the production analysis of low production wells as an example, the analysis time decreased from 1 d in the past to 5 s at present. By logging into one system, analysts can realize multidimensional analysis of low production wells and quickly get an idea of the production performance of low production wells. The process can be traced down step by step from CNPC to company, oilfield, block and single well, making the results more comprehensive and accurate, satisfying the need to know oil and gas production performance of each unit in real time.
3.1. Oil and gas production tracking
The overall production performance of any block can be tracked in real time, and the production trend can be predicted and abnormality in production can be spotted early (Fig. 5). The production indexes such as daily oil production, new well oil production, daily oil production increment of stimulated well, monthly average water-cut, daily water injection volume, composite decline rate, and natural decline rate can be analyzed to predict production trend and spot abnormality in production in time. The abnormality can be traced step by step from oilfield to block and well to find out the reason why the production deviates from the plan. Then a development adjustment plan can be put forward.
Fig. 5.
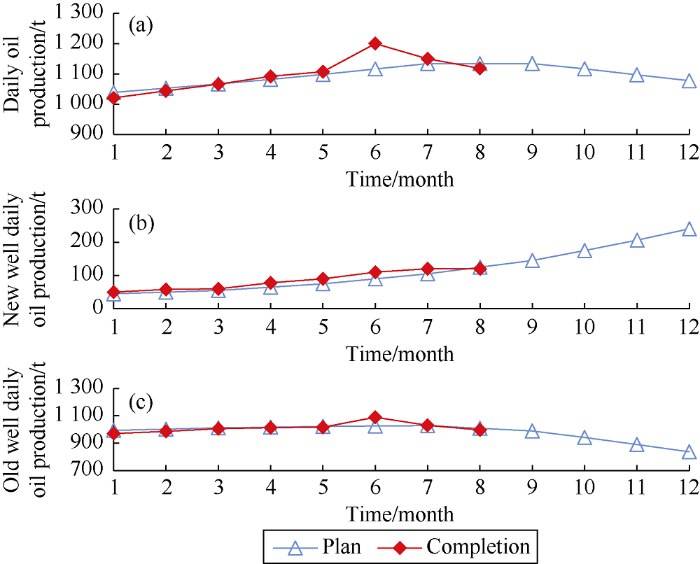
Fig. 5.
Tracking analysis of oil and gas production.
3.2. Early warning of key oilfield production
A quantitative early warning application is established, which makes it possible for one person to monitor the production performance of all oilfields by monthly analyzing the main production indexes, such as daily oil production, rising rate of water cut, and well opening rate (Table 5). A quantitative early warning and monitoring mechanism of oilfield development dynamics is set up to collect production performance data, track the trend of index changes, evaluate oilfield development risk, and send early warning signals to manager. So far, all the oilfields of CNPC have been monitored from multiple perspectives. The production performance of each oilfield is tracked throughout the development cycle. Oilfields or blocks with abnormal production indexes can be filtered from all oilfields, then stimulation measures can be taken in time.
Table 5 Early warning of field production performance.
| Field | Class | Daily oil production/t | Daily water injection/104 m3 | ||||
|---|---|---|---|---|---|---|---|
| JAN | FEB | MAR | JAN | FEB | MAR | ||
| Field 1 | Plan | 26 900 | 27 200 | 27 600 | 12.43 | 12.93 | 12.53 |
| Completion | 26 865 | 24 059 | 25 901 | 12.37 | 12.19 | 12.48 | |
| Warning level | L | H | I | L | I | L | |
| Field 2 | Plan | 11 200 | 11 200 | 11 200 | 12.41 | 13.05 | 13.32 |
| Completion | 10 787 | 9 784 | 10 751 | 12.31 | 11.49 | 12.45 | |
| Warning level | L | H | L | L | H | I | |
3.3. Low production well and long shutdown well production analysis
Potential wells are screened out by analyzing the performance of low production wells and long shutdown wells and stimulation effects with big data technology. At present, most oilfields of CNPC are in the middle and late stage of development, with the number of low production wells and long shutdown wells increasing year by year. The application can analyze the historical and present production trend of low production wells and the main reason of shutdown (Figs. 6-8). The potential wells with good performance after stimulation can be sorted out, to guide the development adjustment of these wells in CNPC and improve well asset utilization.
Fig. 6.

Fig. 6.
Multidimensional analysis of low production wells in different drives.
Fig. 7.
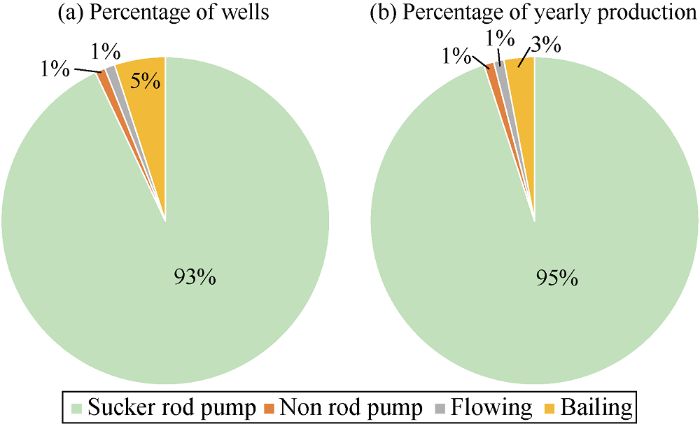
Fig. 7.
Multidimensional analysis of low production wells in different lifting modes.
Fig. 8.
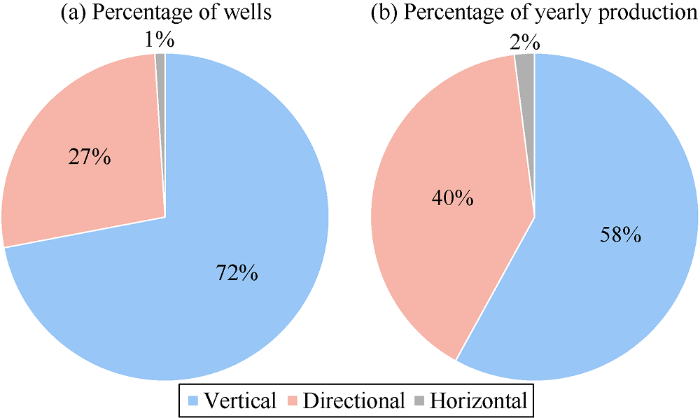
Fig. 8.
Multidimensional analysis of low production well of different types.
3.4. Development laws of different types of reservoirs
The development indexes of the same type of reservoirs from 16 field companies can be compared. The potential of reservoirs can be further exploited by learning from successful development experience. The production processes of all wells from different types of reservoirs such as high permeability sandstone, low permeability sandstone, conglomerate, heavy oil and special lithologic reservoirs can be tracked in real time. Reservoirs with two highs, namely, high water cut of over 80% and recovery percent of reserves of over 60%, reservoirs with two lows, low oil production rate of no more than 0.5% and low recovery percent of geological reserves of less than 10%, and "double negative reservoirs" with negative profit and cash flow can be screened out from all reservoirs. Based on the analysis of the development method, distribution, production performance of different types of reservoirs, the development level of the three types of reservoirs is improved (Table 6).
Table 6 Statistical analysis of development laws by reservoir type.
| Reservoir type | Number of blocks | Number of oil wells | Number of injection wells | Geological reserves/104 t | Reserves/t | Daily oil production/t | Daily water injection/104 m3 | |
|---|---|---|---|---|---|---|---|---|
| Two-high reservoir | High permeability | 5 | 969 | 459 | 7 987 | 3 382 | 120 | 779 |
| Low permeability | 4 | 50 | 23 | 470 | 114 | 3 | 22 | |
| Heavy oil | 2 | 230 | 18 | 796 | 238 | 13 | 85 | |
| Subtotal | 11 | 1 249 | 500 | 9 253 | 3 734 | 136 | 886 | |
| Two-low reservoir | 3 | 247 | 73 | 2 091 | 339 | 21 | 134 | |
| Two-negative reservoir | 2 | 123 | 36 | 1 046 | 170 | 10 | 67 | |
The big data technology enables the central management of the production data of more than 360 thousand oil and gas wells, which is the basis of comprehensive analysis and data mining at the level of CNPC. The value of oil and gas production data will be improved by combining technologies such as oil and gas development, data mining and artificial intelligence, to better support the oil and gas production and scientific research.
4. Conclusions
The multidimensional analysis engine data management platform has been constructed using big data distributed storage and parallel computing, and data warehouse modeling technology, realizing better management and instant query of oil and gas production dynamic big data in distributed storage. The platform can manage centrally the production data of more than 360 thousand oil and gas wells.
Multidimensional analysis subject model of oil and gas well production has been built to preprocess relevant data, as a result, the response time of query is shortened to second level. The applications of oil and gas production tracking, early warning of key field production, low production well and long shutdown well production analysis, classification of development law by reservoir type can replace manual data collection and analysis and enhance work efficiency dramatically. The basic unit of oil and gas production analysis is refined from field to single well, making the production management more detailed. The analysis results can be traced step by step from CNPC to company, field, block and single well, and the results are more comprehensive and accurate, meeting the requirements of learning the oil and gas production performance of each unit in real time.
Nomenclature
A—attributes;
ai—attribute name;
D—dimensions;
di —dimension name;
F—one-to-many mapping from dimensions to attributes;
f—dimension hierarchy;
i, j—index of dimension;
M—measures;
mi—measure name;
n—number of tasks.
Reference
Data as an asset: What the oil and gas sector can learn from other industries about “Big Data”
Interrelationship between big data and knowledge management: An exploratory study in the oil and gas sector
Talking about the development trend of big data in petroleum industry
Preprocessing of the data tapping based on global typical oil and gas field database
Research on distributed data warehouse system for oil and gas drilling information in big data environment
Research and application of oilfield production and operation optimization system based on big data
Development of intelligent drilling big data technology
Synthetic well logs generation via Recurrent Neural Networks
Big data paradox and modeling strategies in geological modeling based on horizontal wells data
Correlation between per-well average dynamic reserves and initial absolute open flow potential(AOFP) for large gas fields in China and its application
Analysis of fire-accident factors using big-data analysis method for construction areas
Traffic big data prediction and visualization using fast incremental model trees-drift detection (FIMT-DD)
Addressing barriers to big data
PrePost+: An efficient N-lists-based algorithm for mining frequent item sets via children-parent equivalence pruning
A parallel algorithm for mining constrained frequent patterns using MapReduce
Mining frequent itemsets using the N-list and subsume concepts
Log mining based on SQL-on-Hadoop query engine and its application
Improving Markov network structure learning using decision trees
Big data: The management revolution
Performance optimization based on Hive
Research on concurrent memory OLAP query optimization technology
Research on OLAP query processing technology for asymmetric memory computing platform
Design and implementation of production data aggregation and management system based on Hive and Apache Kylin
Research on the strategy for temporal information index based on HBase
BigDimETL: ETL for multidimensional big data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}