PETROLEUM EXPLORATION AND DEVELOPMENT, 2021, 48(1): 201-211 doi: 10.1016/S1876-3804(21)60016-2
Production performance forecasting method based on multivariate time series and vector autoregressive machine learning model for waterflooding reservoirs
ZHANG Rui, JIA Hu,*
State Key Laboratory of Oil and Gas Reservoir Geology and Exploitation of Southwest Petroleum University, Chengdu 610500, China
Huo Yingdong Education Foundation Young Teachers Fund for Higher Education Institutions. 171043 Sichuan Outstanding Young Science and Technology Talent Project. 2019JDJQ0036
Abstract
A forecasting method of oil well production based on multivariate time series (MTS) and vector autoregressive (VAR) machine learning model for waterflooding reservoir is proposed, and an example application is carried out. This method first uses MTS analysis to optimize injection and production data on the basis of well pattern analysis. The oil production of different production wells and water injection of injection wells in the well group are regarded as mutually related time series. Then a VAR model is established to mine the linear relationship from MTS data and forecast the oil well production by model fitting. The analysis of history production data of waterflooding reservoirs shows that, compared with history matching results of numerical reservoir simulation, the production forecasting results from the machine learning model are more accurate, and uncertainty analysis can improve the safety of forecasting results. Furthermore, impulse response analysis can evaluate the oil production contribution of the injection well, which can provide theoretical guidance for adjustment of waterflooding development plan.
Keywords:waterflooding reservoir
;
production prediction
;
machine learning
;
multivariate time series
;
vector autoregression
;
uncertainty analysis
ZHANG Rui, JIA Hu. Production performance forecasting method based on multivariate time series and vector autoregressive machine learning model for waterflooding reservoirs. [J], 2021, 48(1): 201-211 doi:10.1016/S1876-3804(21)60016-2
Introduction
With the application and popularization of artificial intelligence technology in petroleum industry, oilfields have entered the era of information and intelligence[1,2]. Every link of oilfield development has accumulated a large amount of historical production data. The data is diverse in form and complex in structure, posing challenge to the traditional analysis and prediction method, so it is necessary to develop an intelligent production data analysis and prediction method.
Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019.
It can be seen that previous studies mainly solved the problem of oilfield production data analysis and prediction by establishing prediction model. However, large oilfields with a large number of wells often have a long production history, complex well history, and flow field of different well groups varying greatly at different times. In order to accurately characterize the relationship between oil production of producers and injected water volume of injectors in a well group, it is necessary to establish a model for accurate prediction of complex multi-process time series. In this paper, a production prediction method for waterflooding reservoirs based on multivariable time series (MTS) and vector autoregressive (VAR) machine learning model is presented. On the basis of well pattern analysis, the data of well groups are selected by MTS analysis, and the oil production and injection water of different wells in a well group are regarded as the time series related to each other, then the VAR model is established to extract interaction law from multiple time series, find out the dependence between injector/producer flows, and predict oil well production through model fitting. Uncertainty analysis and impulse response analysis are used to evaluate the water injector effect.
1. Methodology
1.1. Multivariate time series analysis
Time series is a series of values with the same statistical indicator arranged in chronological order of occurrence. If a variable can be observed in a time series, and the past data contains information about the future changes of the variable, a function of past observation data can be used to predict future value of the variable[22]. There is time series observation data in the historical production data of waterflooding reservoirs, such as oil well production, and the past oil production data contains the change information of future oil production. The historical data of oil production can be used to predict the future oil production. When dealing with historical production data variables, a variable usually depends not only on the past value of this variable, but also on other variables in time. For example, the variation of oil production of one well in a reservoir may depend on the change of water injection in multiple injectors in the reservoir. For historical production data of waterflooding reservoirs with many wells, it is difficult to excavate the data relationship between multiple injectors and producers by single variable time series analysis, so it is necessary to carry out multivariate time series analysis.
Correlation analysis is the key to MTS analysis, which refers to the analysis of the interdependence between two or more variables to measure the degree and direction of correlation between variables and excavate the inner relationship between variables[23]. The correlation coefficient is an index to measure the correlation degree between two variables. The Pearson correlation coefficient is used to measure the linear correlation degree between two variables[24]. Suppose there are n data pairs (aq, bq) about variables of a and b, q=1, 2,…, n, then calculation formula of Pearson correlation coefficient is as follow:
where the value range of r is [-1, 1]; the sign of r indicates the direction of correlation between the variables, r>0 represents linear positive correlation, r<0 denotes linear negative correlation; |r| can be used to quantitatively analyze the degree of linear correlation between the variables. Pearson linear correlation evaluation criterion is: |r|=0 indicates linear independence, 0<|r|<0.3 indicates low linear correlation, 0.3≤|r|<0.8 indicates medium linear correlation, 0.8≤|r|<1.0 indicates highly linear correlation, |r|=1.0 indicates completely linear correlation.
For the flow rate of wells in waterflooding reservoir, oil production of producers and water injection of injectors in the reservoir can be taken as multivariate time series, and the correlation analysis can be carried out by using the Pearson correlation coefficient. According to Eq. (1), the MTS correlation analysis formula for the flow rates of multiple wells can be deduced:
To enhance the stability of training process of machine learning model and the rationality of production prediction results, the MTS correlation analysis results can be used to select the injector/producer flow rate data of waterflooding reservoirs. According to the evaluation criteria of Pearson linear correlation degree and the Pearson correlation coefficient calculated by Eq. (2), the following selection formula of injector/producer flow rate data can be obtained:
The data selection process represented by Eq. (3) can ensure that there is a medium or higher linear correlation between the flow rate of a producer (injector) and the flow rate of at least one injector (producer), which makes it easy for the machine learning model to mine the dependence of the flow rate between injector/producer pair.
1.2. Vector autoregressive model
Machine learning models can be divided into two categories according to the data types: supervised learning models and unsupervised learning models, in which supervised learning models mainly include models for classification and regression. Vector autoregressive model is a kind of machine learning model for regression. This model is mainly used to deal with multivariable time series data. Through VAR model, we can excavate the linear dependence between multiple time series data. VAR model is a combination and extension of autoregressive model and equations, and is an unstructured regression model with multiple equations. Any variable in the model can be represented by an equation composed of its own lag value, other related variables, constant term and error term, and the future value of a variable can be predicted by iteration[25].
VAR model of inter-well flow rate is not based on reservoir engineering theory, but based on the statistical relationships between the injector/producer flow rate data. First of all, the oil well production and the water injection are taken as two time series related to each other, and the following vector is constructed:
The prediction model takes the oil well production in the current month Yt, the oil well production in the previous p-1 months (Yt-1, Yt-2, …, Yt-p+1) and the water injection in the next month Et+1 as inputs, and then predicts the oil production of the well in the next month $\hat{\boldsymbol{Y}}_{t+1}$ by interation. The iterative formula is as follows:
$\hat{A}_{1}, \quad \hat{A}_{2}, \ldots, \quad \hat{A}_{p}, \quad \hat{B}_{0}$ in the Eq. (6) are the estimation parameter matrix, they can be solved by simultaneous linear equations, as shown in Eq. (7).
Finally, the equations can be solved by the least square method, and the least square solution $\hat{D}$ of total parameter matrix D can be written as:
In the VAR model given in Eq. (5), an important parameter is the lag order p, which represents the maximum previous p months of the oil well production (Yt-1, Yt-2, …, Yt-p) will affect the oil well production in the current month Yt. The choice of lag order will directly affect the stability and accuracy of VAR model, too larger lag order will lead to the increase of estimation parameters, affecting the validity of model parameter estimation, and too small lag order will lead to autocorrelation of error terms, affecting the consistency of model parameter estimation. The lag order is generally determined according to the information criterion. The Eq. (9) is firstly used to calculate the likelihood estimation value L of the VAR model when the lag order is p, then combined with likelihood estimation and model parameters, three information criteria as shown in Eq. (10) can be obtained[26,27,28]. Finally, the lag order which makes the evaluation values of the three information criteria smaller is taken as the best lag order.
Although the lag order analysis can guarantee the stability and accuracy of the VAR model, the prediction results still have some errors when the given amount of data is small. The uncertainty analysis can estimate the model error caused by the previous data, and give the model confidence of the prediction results, so as to make safer prediction, that is, to make careful decisions when the prediction uncertainty is large. Therefore, it is necessary to analyze the uncertainty of the model prediction results. Derivation of the uncertainty of prediction results is based on considering the original time series process as a random process[25] and its concise matrix is as follows:
Meanwhile, considering the continuous influence of the parameters, the cumulative effect matrix at a certain time in the future has the following relationship with the estimated prediction error:
VAR model can not only carry out uncertainty analysis, but also evaluate the system through impulse response analysis[25], that is, the injector can be evaluated by impulse response analysis after the model fitting is completed. The evaluation basis is to increase the daily injection rate of any injector by a fixed value (usually 1 m3) and observe its effect on the entire model system. The impulse response analysis formula of injector can be written as follows:
The MTS and VAR machine learning models can be used to predict the production of oil wells in waterflooding reservoirs. The model framework is shown in Fig. 1, which mainly includes the following five modules.
Fig. 1.
Framework of MTS and VAR machine learning model.
(1) Time series extraction module. The historical production data of waterflooding reservoir is taken as the model input, and the time series of oil production and water injection are extracted according to the data label and time index.
(2) MTS analysis module. Based on well history analysis,well groups are divided, the time series in the development period of well groups are intercepted from all the injection and producer time series, and then the MTS correlation analysis is carried out by using Eq. (2). The flow rate data of injection and producer group are selected by Eq. (3).
(3) Data preprocessing module. The selected well flow rate data are normalized and smoothed to increase the stability of the data and reduce the difficulty of fitting, and the data are divided into training set and verification set.
(4) VAR model prediction module. The module is the core of the model, which includes four steps: firstly, the VAR model is established according to Eq. (5); secondly, the lag order is analyzed according to the information criterion given by Eq. (10) to find out the best lag order; then, the oil production prediction algorithm is constructed according to Eq. (6); finally, the VAR model is fitted by using the training set, and then used to predict the validation set.
(5) Analysis and evaluation module. Firstly, error analysis of VAR model is carried out, the error between the prediction data and the actual data of the validation set is taken as evaluation standard to ensure the accuracy of forecast results, and then the uncertainty analysis is carried out by using Eq. (12) to improve the safety of forecast results. Finally, Eq. (13) is used for impulse response analysis, and then the oil recovery contribution of injectors is evaluated.
3. Case study
A fault block reservoir in a block of Dagang Oilfield was taken as the research object, where there are 105 producers and 66 injectors in the main fault control area. This area has abundant faults and the reservoirs have strong heterogeneity. The geological model built for the reservoir has 54 layers. Because of the complex reservoir geological model, the numerical reservoir simulation method has poor convergence, making the history matching difficult and low in accuracy. Based on the data label and time index of monthly daily oil production and daily water injection data, we extracted the time series of oil production of the producers and injection volume of water injector from the historical production data of the fault block reservoir, including 171 groups of data in total, each group with 573 time samples, from July 1970 to March 2018. Fig. 2 shows the historical production data of two wells, producer X42-7-3 and water injector X43-67. On the basis of well group analysis, the MTS and VAR machine learning model were used to deal with the flow rate time series of injectors and producers, then to predict and analyze the oil production of the producers. The oil recovery contributions of the injectors were evaluated.
Fig. 2.
Historical production data of producer X42-7-3 and injector X43-67.
3.1. MTS correlation analysis
On the basis of well history analysis, the well groups were divided. In order to reduce the influence of development adjustment and measures on production data and ensure the reliability of forecast results, the following well history was considered: (1) Infill well, no new wells were added to the well group; (2) layer adjustment, the main development layer was not adjusted; (3) converting to water injector, there was no producer converted to injector during the development period; (4) well shut-down, allowing temporary shut-down. Table 1 shows the results of well group division based on well history analysis. A total of 10 well groups were selected. The well groups differ in number of producers and injectors, main development layer, and development time period.
Table 1
Table 1The result of well group division based on well history analysis.
By using Eq. (2), we analyzed the correlations between the oil production time series and water injection time series of the 10 well groups, and obtained the correlation diagram of the flow rate time series of the injectors and producers. The time series correlation diagrams of 4 well groups are shown in Fig. 3. Based on the evaluation standard of Pearson linear correlation degree, it can be seen from Fig. 3 that the injectors and producers in well group No. 6 have stronger correlation in flow rate, while injectors and producers in well group No. 4 and No. 10 have poorer correlation in flow. Fig. 4 shows the flow rate time series of the injector/producer pair with the highest correlation in well group No. 6. The flow rates of these two wells have a correlation coefficient of 0.86, belonging to highly linear correlation. It can be seen from the time series diagram that these two wells had flow rate increase or decrease at the same time. For well group No. 4 and No. 10, because the two well groups are near the fault zone, the fluid flow in the formation is complex, and the flows of injectors and producers in them have poorer correlation generally.
Fig. 3.
Correlation diagram of flow time series of 4 well groups (the value in blue circle is correlation coefficient, the size of circle represents the absolute value of correlation coefficient).
Fig. 4.
Flow rate time series diagram of the injector/producer pair with the highest correlation in well group No. 6.
The data of well groups were selected by using Eq. (3), only the data with high correlation were retained, and the results after selection are showed in Table 2. The average value of |Rij| was used to characterize the correlation degree, it can be seen that the well groups differ in correlation. In addition, compared with the data in Table 1, production of some well groups with low correlation, such as well group No. 4 and No. 10, wouldn’t be pre-dicted. At the same time, the injectors and producers with low correlation in some well groups wouldn’t be considered anymore, such as Well X47-4-2 of well group No. 1 in Fig. 3. After the data selection of well groups, the VAR model was established for the injection-production well pattern system.
In order to ensure the stability of the model fitting and forecast results, the selected flow rate data were normalized and smoothed to increase the stability of the data. The data of the last 10 months during the well group development period were taken as the verification set and the remaining data as the training set. After preprocessing of the data, we fitted and predicted the VAR models of 8 well groups. We discussed the results of well group No. 6 with the highest overall correlation mainly. Fig. 5 shows the well location diagram of well group No. 6. Before model fitting, lag order analysis is needed to determine the best lag order. Using Eq. (9) and Eq. (10), the evaluation values of corresponding AIC, BIC and HQIC information criterion were calculated at different values of lag order. Table 3 shows the lag order analysis results of the VAR model of well group No. 6. It can be seen that the lag order corresponding to the smallest evaluation values of the three information criteria is 2, so we chose 2 as the best lag order.
After the optimal lag order was determined, the model fitting and prediction was started. Fig. 6 shows the forecast results of the validation set data of two wells, X50-5-1and X50-7-2, in well group No. 6. It can be seen that the predicted daily output is basically consistent with the actual daily output. The production data points of the two wells have an average relative error of 0.036 49 and 0.012 60 respectively. The small deviation between the predicted data and the actual data proves the accuracy of the forecast results.
Fig. 6.
Forecast results of validation set data of wells X50-5-1 and X50-7-2 in well group No. 6.
We analyzed the predicted data of all producers in the verification set data in well group No. 6 and compared with the history matching results of numerical simulation, and the results are shown in Table 4. It can be seen that the forecasting results of all wells except X51-5-1 have higher accuracy. According to the time series correlation diagram of well group No. 6 in Fig. 3, the correlation between well X51-5-1 and the injector is not high, which has a certain influence on the prediction accuracy of machine learning model. Then the uncertainty of well X51-5-1 with larger error was analyzed, the results are shown in Fig. 7. It is found that although its prediction error is large, its range of prediction uncertainty basically includes the actual data, ensuring the security of the forecast results.
Table 4
Table 4Forecast results of all producers in well group No. 6.
Fig. 7.
Uncertainty analysis of forecast results of well X51-5-1 in well group No. 6.
Comparison of the results of machine learning and history matching in Table 4 shows the overall relative error of history matching is large, among which the history matching of well X50-5-1 has the largest relative error. Looking at the history matching curve of this well (Fig. 8), it can be found that due to the complex reservoir model, the history matching in the middle development period is higher in accuracy, but low in accuracy in the early and late development periods, especially in the late development period, the output of history matching increased, quite difference from the actual output, in other words, the relative error is large. In contrast, the machine learning results of the well have very small errors. Looking close at the machine learning curve of the well (Fig. 8), it can be seen that, although the production data fluctuates greatly in the early stage of development for which history matching is more difficult, the preprocessing of the data increases the level of data stability, which guarantees the stability of VAR model fitting and prediction; the production data is relatively stable in the middle and late stages of development, so the VAR model can fit and predict the change trend of oil production quite well.
Fig. 8.
Fitted output of well X50-5-1 in well group No. 6.
The adaptability of machine learning model mainly depends on the quantity and quality of data. Table 5 shows the forecast results of cumulative outputs of all producers in the 8 well groups. It can be seen that well groups No. 3, No. 6 and No. 8 have smaller relative errors, while well groups No. 1 and No. 9 have large relative errors. From the data analysis in Table 1, it can be found that the amount of data has no significant effect on the fitting and prediction accuracy of the VAR model. By contrast, the quality of data is the key to ensuring the reliability and applicability of the VAR model. From the analysis of the average of |Rij| in Table 2, it is found that the larger the average value of the |Rij|, the higher the prediction accuracy of the machine learning model of the well group, which indicates that this parameter can be used to evaluate the adaptability of the machine learning models of different well groups. Comparing the average values of |Rij| of well groups No. 1 and No. 9, it is found that although the average of |Rij| of well group No. 9 is larger than that of well group No. 1, the relative error of well group No. 9 is larger. It is found from Table 2 that the injectors and producers in well group No. 9 are obviously more than those in well group No. 1, which indicates that the number of injectors and producers in a well group will also have a certain impact on the forecast results of cumulative output of the well group. Comparison of the results of machine learning and history matching in Table 5 shows that the prediction results of machine learning model have overall relative error smaller than those of history matching, which indicates that the VAR model has better prediction effect on the cumulative output of well group.
Table 5
Table 5Predicted results of cumulative outputs of all producers in each well group.
The oil recovery contribution of an injector can be evaluated through impulse response analysis. The specific method is to observe the effect of an injector on other producers by assuming that the average daily injection volume of the injector increases by 1 m3, in the same month. The calculation formula is as Eq. (13). Fig. 9 shows the effects of two injectors in well group No. 6, well X50-6 and X50-7 on the production of all producers in this well group. For example, the effect of 0.05 m3 represents an increase of 0.05 m3 in daily production of all the producers, the effect of -0.01 m3 represents a decrease of 0.01 m3 in the daily production of all producers, and so on. It can be seen that the effect decreases with time. Fig. 10 shows the cumulative effects of these two injectors over time, and the results represent a long-term effect. It can be seen that the two injectors have opposite cumulative effects, indicating that they have obviously different oil displacement potential in the short term. Therefore, the cumulative effect of the injectors in March 2018 on the outputs of all the producers can be used as an evaluation index to evaluate the displacement potential of the injectors. The cumulative effects of the three injectors X50-6, X50-7 and X50-8 were 0.916, -0.156, -0.055 m3, respectively. It can be seen that the injector X50-6 had greater cumulative effect, indicating that it has higher oil displacement potential. In contrast, wells X50-7 and X50-8 had negative cumulative effect, which indicates that they had negative effects on the outputs of all the producers. Although the cumulative effect of well X50-8 is negative, its absolute value is very small, which indicates that this well had smaller negative effect on the outputs of all producers. In the practical production, the project decision maker can optimize the water injection plan of the well group according to the results of the pulse response analysis of the injectors to improve the production of waterflooding reservoirs.
Fig. 10.
Cumulative effects of injectors X50-6 and X50-7 on the outputs of all producers in well group No. 6.
4. Conclusions
A forecast method of oil well production based on MTS and VAR machine learning model for waterflooding reservoir is presented. Based on well pattern analysis, this method extracts interaction laws of multiple time series by using machine learning model, to excavate the dependence of flow rates between injector/producer, and predict oil well production by model fitting. At the same time, impulse response analysis is used to evaluate the effect of water injector, which provides theoretical guidance for further water injection adjustment. The method is less subjective and can do evaluation without expert experience, and can do uncertainty analysis to ensure the safety and accuracy of the predicted results. It should be noted that for some well groups, the machine learning method is not fully applicable because of the complex flow laws of underground fluid, and the prediction accuracy of some well groups with low correlation is not high. It is necessary to combine this machine learning method with reservoir engineering methods for comprehensive evaluation.
Nomenclature
a, b—variable;
A1, A2, …, Ap—the first order, second order, ..., p order producer parameter matrix, used to describe the flow rate relationship between different producers;
The common critical criterion and nonlinear search method were adopted for the study of connected operation envelopes of deepwater drilling riser and a riser-wellhead-conductor integral finite element model was established. The combination parameters of drilling platform offset, current speed and slip joint stroke were used to determine the riser operability envelopes. The results show that the drilling envelope has an upconing shape and is limited by lower flex joint angle when the surface current speed is low (less than 1.0 m/s). In downstream direction, when the current speed increases, the rotation angle of the lower flex joint increases and the allowable maximum offset of the platform reduces, but in upstream direction, the conditions will be opposite. When surface current speed exceeds 1.0 m/s, the drilling envelope is limited by upper flex joint angle. When it is in upstream direction, the increase of current flow will increase the rotor angle of the upper flexible joint and reduce the drilling envelope rapidly. The non-drilling envelope and emergency disconnect sequence (EDS) actuation envelope are mainly subject to the maximal equivalent stress of the conductor and they will drift towards the upstream direction with the increase of current speed. In addition, through the analysis on influence factors of connection window operation of riser, the tensile force at the top could be increased and drilling fluid density could be reduced properly, so that the drilling envelope could be expanded.
LIJ, CASTAGNAJ, LID, et al.
Reservoir prediction via SVM pattern recognition: SEG Technical Program Expanded Abstracts 2004
Tulsa: Society of Exploration Geophysicists, 2004: 425-428.
SALAZARM, GONZALEZH, MATRINGES, et al. Combining decline-curve analysis and capacitance-resistance models to understand and predict the behavior of a mature naturally fractured carbonate reservoir under gas injection. SPE 153252 , 2012.
LIJ, LEIZ, LIS, et al. Optimizing water flood performance to improve injector efficiency in fractured low-permeability reservoirs using streamline simulation. SPE 182779, 2016.
MAQUIA F, ZHAIX, SUAREZN A, et al. A comprehensive workflow for near real time waterflood management and production optimization using reduced-physics and data-driven technologies. SPE 182696 , 2017.
Discussion on current application of artificial intelligence in petroleum industry
1
2019
... With the application and popularization of artificial intelligence technology in petroleum industry, oilfields have entered the era of information and intelligence[1,2]. Every link of oilfield development has accumulated a large amount of historical production data. The data is diverse in form and complex in structure, posing challenge to the traditional analysis and prediction method, so it is necessary to develop an intelligent production data analysis and prediction method. ...
Key technologies and understandings on the construction of smart fields
1
2012
... With the application and popularization of artificial intelligence technology in petroleum industry, oilfields have entered the era of information and intelligence[1,2]. Every link of oilfield development has accumulated a large amount of historical production data. The data is diverse in form and complex in structure, posing challenge to the traditional analysis and prediction method, so it is necessary to develop an intelligent production data analysis and prediction method. ...
Reservoir prediction via SVM pattern recognition: SEG Technical Program Expanded Abstracts 2004
1
2004
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Oilfield output forecast using fuzzy neural network
1
2005
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2009
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2011
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2012
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2012
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Data mining methodologies enhance probabilistic well forecasting
1
2013
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Application of improved grey neural network model to oil yields
1
2013
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Production forecasting in unconventional resources using data mining and time series analysis
1
2014
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Evaluating gas production performances in Marcellus using data mining technologies
1
2014
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2016
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2016
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
An interwell connectivity inversion model for waterflooded multilayer reservoirs
1
2016
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2017
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Research and application of oilfield production forecast technology based on data mining in Spark environment
1
2017
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2017
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Oil reservoir water flooding flowing area identification based on the method of streamline clustering artificial intelligence
1
2018
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
1
2019
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
An intelligent data driven approach for production prediction
1
2019
... Rational introduction of artificial intelligence method and establishment of machine learning model suitable for oilfield data are the key to intelligent analysis of oilfield data. Li et al.[3] proposed a reservoir prediction method based on support vector machine (SVM) technique in 2004. Xing et al.[4] proposed an oil production prediction model based on fuzzy neural network in 2005. Weber et al.[5] advanced a capacitive reactance model (CRM) based on the linear and nonlinear regression method to characterize the connectivity between each injector/producer pair, which can be used to work out the water injection scheme able to maximize reservoir output in 2009. Anifowose et al.[6] reviewed the application of artificial intelligence technology in petroleum engineering, and summarized the applications of this technology in reservoir modeling and production management in 2011. Gherabati et al.[7] established a neural network model by taking the position of any injector in any formation as the node of the model and fitted production history by minimizing the mean square error between the simulation results and the actual production data in 2012. Salazar et al.[8] predicted the output of any producer by combining the attenuation curve with the capacitive reactance model based on superposition principle in 2012. Holdaway[9] worked out a probability model integrating guidance, clustering and data mining to forecast production in 2013. Zhang et al.[10] proposed a production prediction model based on improved gray network by combining the advantages of back propagation neural network with gray network in 2013. Gupta et al.[11] put forward a production prediction method based on data mining technology and time series analysis in 2014. Zhou et al.[12] used multivariate regression analysis, cluster analysis and principal component analysis to identify the correlation between production capacity and geological engineering parameters. Li et al.[13] built a water injection distribution model of multi-layer waterflooding reservoirs with support vector machine as the core which took the liquid production profile and injection profile data as the target variables, and permeability, reservoir thickness, well spacing, injection speed and liquid production as the influencing factors in 2016. Cao et al.[14] predicted the production status of old and new wells in unconventional reservoirs based on the information of geological model, historical production data and production system by machine learning algorithm in 2016. Zhao et al.[15] firstly discretized the reservoir into a series of inter-well connected units characterized by inter-well conductivity and connected volume, then built an inter-well connectivity inversion model for multi-layer waterflooding reservoirs and proposed the corresponding model parameter inversion method in 2016. Maqui et al.[16] combined the traditional numerical simulation method with pure data prediction method to transform the flow field into a network connection diagram of injection-producers suitable for the optimization method in 2017. Wu[17] worked out a reservoir data processing and analysis method based on Spark to analyze the relationship between oilfield production data and reservoir parameters using data mining technology in 2017. Martin et al.[18] proposed an automated data-driven method for production prediction using a two-step machine learning scheme in 2017. Jia et al.[19] carried out fine description of flow field based on the method of streamline clustering artificial intelligence to find out the potential dominant flow field in 2018. Khan et al.[20] advanced an empirical model of crude oil flow estimation to predict the oil production rate of artificial gas lift wells by using artificial neural fuzzy inference system (ANFIS) and SVM algorithm in 2019. Noshi et al.[21] explored the potential applications of three machine learning algorithms, gradient boosting tree (GBT), Adaboost, and support vector regression (SVR), in production prediction in 2019. ...
Review of time series prediction methods
1
2019
... Time series is a series of values with the same statistical indicator arranged in chronological order of occurrence. If a variable can be observed in a time series, and the past data contains information about the future changes of the variable, a function of past observation data can be used to predict future value of the variable[22]. There is time series observation data in the historical production data of waterflooding reservoirs, such as oil well production, and the past oil production data contains the change information of future oil production. The historical data of oil production can be used to predict the future oil production. When dealing with historical production data variables, a variable usually depends not only on the past value of this variable, but also on other variables in time. For example, the variation of oil production of one well in a reservoir may depend on the change of water injection in multiple injectors in the reservoir. For historical production data of waterflooding reservoirs with many wells, it is difficult to excavate the data relationship between multiple injectors and producers by single variable time series analysis, so it is necessary to carry out multivariate time series analysis. ...
A survey on correlation analysis of big data
1
2016
... Correlation analysis is the key to MTS analysis, which refers to the analysis of the interdependence between two or more variables to measure the degree and direction of correlation between variables and excavate the inner relationship between variables[23]. The correlation coefficient is an index to measure the correlation degree between two variables. The Pearson correlation coefficient is used to measure the linear correlation degree between two variables[24]. Suppose there are n data pairs (aq, bq) about variables of a and b, q=1, 2,…, n, then calculation formula of Pearson correlation coefficient is as follow: ...
Mathematical contributions to the theory of evolution (Ⅲ):Regression, heredity, panmixia
1
1896
... Correlation analysis is the key to MTS analysis, which refers to the analysis of the interdependence between two or more variables to measure the degree and direction of correlation between variables and excavate the inner relationship between variables[23]. The correlation coefficient is an index to measure the correlation degree between two variables. The Pearson correlation coefficient is used to measure the linear correlation degree between two variables[24]. Suppose there are n data pairs (aq, bq) about variables of a and b, q=1, 2,…, n, then calculation formula of Pearson correlation coefficient is as follow: ...
New introduction to multiple time series analysis
3
2005
... Machine learning models can be divided into two categories according to the data types: supervised learning models and unsupervised learning models, in which supervised learning models mainly include models for classification and regression. Vector autoregressive model is a kind of machine learning model for regression. This model is mainly used to deal with multivariable time series data. Through VAR model, we can excavate the linear dependence between multiple time series data. VAR model is a combination and extension of autoregressive model and equations, and is an unstructured regression model with multiple equations. Any variable in the model can be represented by an equation composed of its own lag value, other related variables, constant term and error term, and the future value of a variable can be predicted by iteration[25]. ...
... Although the lag order analysis can guarantee the stability and accuracy of the VAR model, the prediction results still have some errors when the given amount of data is small. The uncertainty analysis can estimate the model error caused by the previous data, and give the model confidence of the prediction results, so as to make safer prediction, that is, to make careful decisions when the prediction uncertainty is large. Therefore, it is necessary to analyze the uncertainty of the model prediction results. Derivation of the uncertainty of prediction results is based on considering the original time series process as a random process[25] and its concise matrix is as follows: ...
... VAR model can not only carry out uncertainty analysis, but also evaluate the system through impulse response analysis[25], that is, the injector can be evaluated by impulse response analysis after the model fitting is completed. The evaluation basis is to increase the daily injection rate of any injector by a fixed value (usually 1 m3) and observe its effect on the entire model system. The impulse response analysis formula of injector can be written as follows: ...
Information theory and an extension of the maximum likelihood principle
1
1973
... In the VAR model given in Eq. (5), an important parameter is the lag order p, which represents the maximum previous p months of the oil well production (Yt-1, Yt-2, …, Yt-p) will affect the oil well production in the current month Yt. The choice of lag order will directly affect the stability and accuracy of VAR model, too larger lag order will lead to the increase of estimation parameters, affecting the validity of model parameter estimation, and too small lag order will lead to autocorrelation of error terms, affecting the consistency of model parameter estimation. The lag order is generally determined according to the information criterion. The Eq. (9) is firstly used to calculate the likelihood estimation value L of the VAR model when the lag order is p, then combined with likelihood estimation and model parameters, three information criteria as shown in Eq. (10) can be obtained[26,27,28]. Finally, the lag order which makes the evaluation values of the three information criteria smaller is taken as the best lag order. ...
Estimating the dimension of a model
1
1978
... In the VAR model given in Eq. (5), an important parameter is the lag order p, which represents the maximum previous p months of the oil well production (Yt-1, Yt-2, …, Yt-p) will affect the oil well production in the current month Yt. The choice of lag order will directly affect the stability and accuracy of VAR model, too larger lag order will lead to the increase of estimation parameters, affecting the validity of model parameter estimation, and too small lag order will lead to autocorrelation of error terms, affecting the consistency of model parameter estimation. The lag order is generally determined according to the information criterion. The Eq. (9) is firstly used to calculate the likelihood estimation value L of the VAR model when the lag order is p, then combined with likelihood estimation and model parameters, three information criteria as shown in Eq. (10) can be obtained[26,27,28]. Finally, the lag order which makes the evaluation values of the three information criteria smaller is taken as the best lag order. ...
The determination of the order of an autoregression. Journal of the Royal Statistical Society
1
1979
... In the VAR model given in Eq. (5), an important parameter is the lag order p, which represents the maximum previous p months of the oil well production (Yt-1, Yt-2, …, Yt-p) will affect the oil well production in the current month Yt. The choice of lag order will directly affect the stability and accuracy of VAR model, too larger lag order will lead to the increase of estimation parameters, affecting the validity of model parameter estimation, and too small lag order will lead to autocorrelation of error terms, affecting the consistency of model parameter estimation. The lag order is generally determined according to the information criterion. The Eq. (9) is firstly used to calculate the likelihood estimation value L of the VAR model when the lag order is p, then combined with likelihood estimation and model parameters, three information criteria as shown in Eq. (10) can be obtained[26,27,28]. Finally, the lag order which makes the evaluation values of the three information criteria smaller is taken as the best lag order. ...



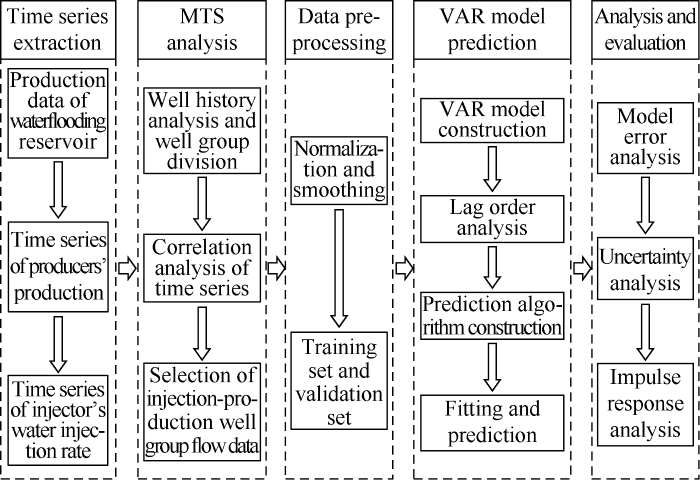
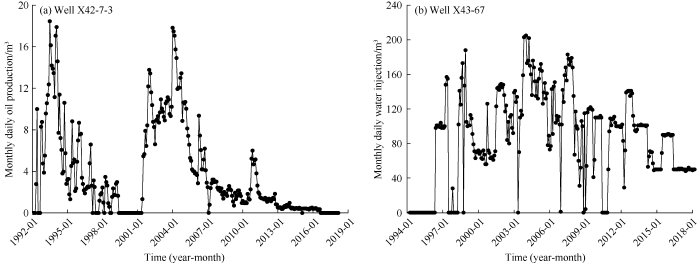
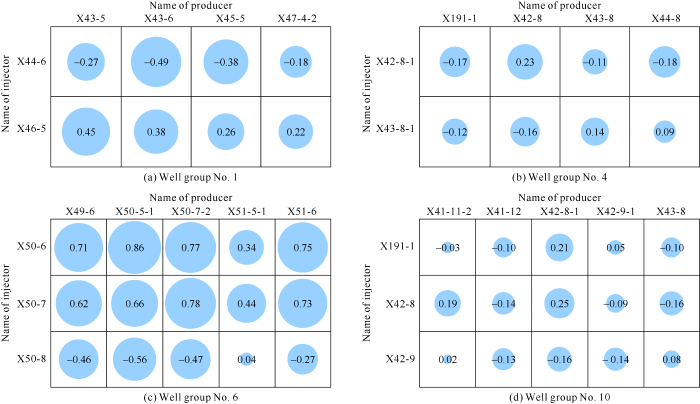
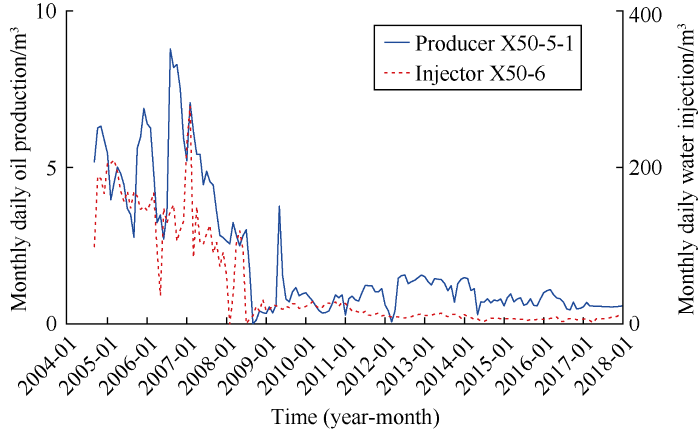
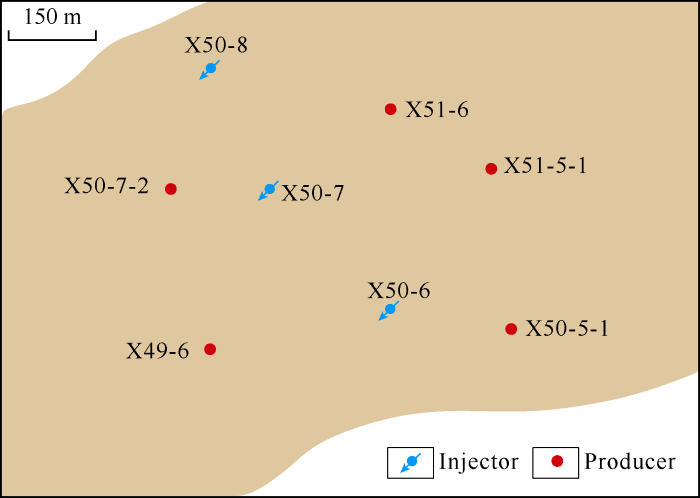
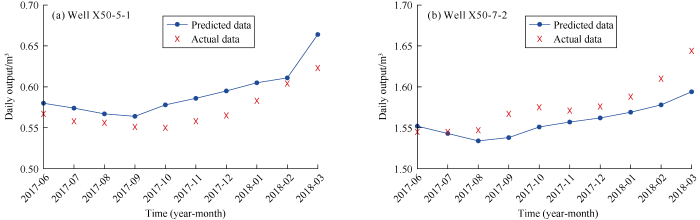
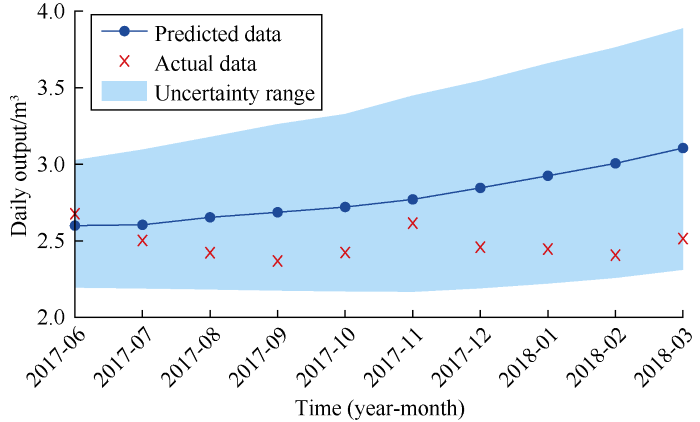
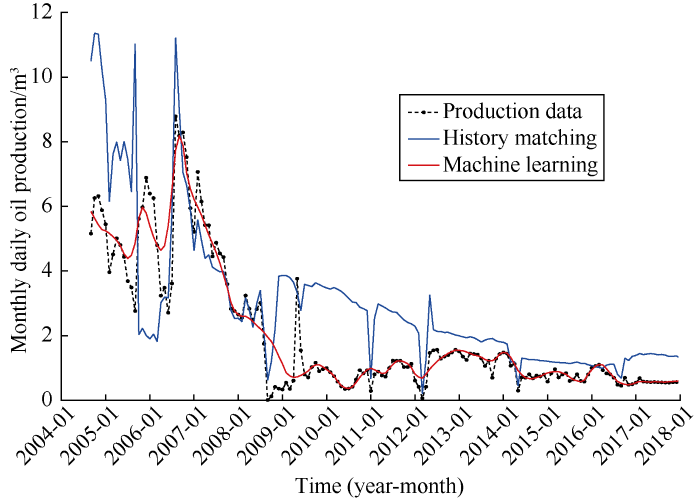
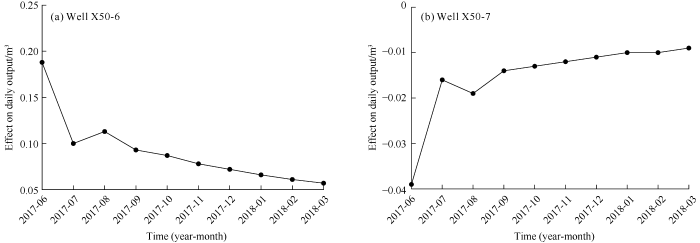
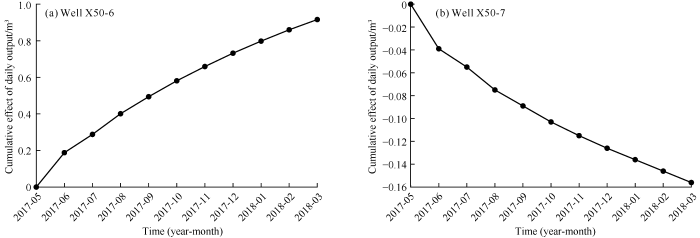


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}