

Introduction
With the rapid development of deep learning technology and hardware computing power, the number of parameters and training data for deep neural network models is constantly increasing. In natural language processing, researchers have found that increasing the number of parameters and training data can improve the performance and generalization of language models. This has even led to the "emergence" phenomenon, where language models exhibit significant performance improvements in certain tasks. These language models with extended parameters and data are called Large Language Models (LLMs). To further extend this concept to other areas, such as computer vision, the Stanford Human- Centered Artificial Intelligence Institute has proposed the concept of the Foundation Model, which refers to a model trained (typically through self-supervised pre-training) on large amounts of data. The trained model can be adapted to various downstream tasks. Subsequently, Chinese researchers proposed a similar concept known as the Large Model, referring to models with many parameters, trained on massive data, and exhibiting excellent generalization across data and tasks. Therefore, to a certain extent, the concepts of the Large Model and the Foundation Model are equivalent.
Compared to traditional AI techniques such as deep learning, large models show three characteristics: generalization, generality, and emergence. Generalization denotes the model's ability on unseen data. Large models have good generalizations, allowing them to appropriately adapt to and deal with unseen situations. Generality is the ability of a model to handle a wide variety of tasks, with large models performing well across a broad range of task types without requiring special customization or retraining for each new task. Emergence refers to the ability of a model, when it reaches a certain size and complexity, to demonstrate capabilities or behaviors that are not present in small or simple models. Large models, especially some pre-trained models, show strong powers in Few-shot Learning and Zero-shot Learning scenarios, providing reasonable answers or solutions even for tasks unseen in the training data. However, large models also have some drawbacks. For example, they usually require immense computational resources for training and deployment, may codify and amplify biases present in the data, and are not as accurate as specialized models in understanding specific details or domain-specific knowledge.
China has provided significant attention and support to the development of large models at the national level, vigorously promoting the industry of large models through policy initiatives and financial investment. In the past year, large models have rapidly developed vertical applications in many industries, including law, healthcare, and urban construction, demonstrating great potential and value. With the deterioration of the quality of China's oil and gas resources, the difficulty of exploration and development for oil and gas is gradually increasing, necessitating new methods to improve quality and efficiency. Large models provide solutions to the challenges of "small samples" and "comprehensive analysis of multimodal data" faced by AI applications in the oil and gas industry. This paper summarizes the current research status of large model technology both domestically and internationally, reviews their vertical applications in general industry and the oil and gas industry, discusses the main problems and challenges faced by the oil and gas industry in the process of large model application, and offers prospects for the application of large models in the oil and gas industry with specific examples.
1. Concept and development of large model technology
Although the academic community has not yet established a unified standard to define whether a model is a large model, there are some common criteria to recognize large models, including the number of parameters, the amount of training data, generalization ability, and adaptability. Specifically, for the number of parameters, large models usually have hundreds of millions to billions or even more parameters; concerning the amount of training data, large models are typically trained on datasets containing millions to billions of samples (regardless of whether the training data has labels); regarding generalization ability, large models show good performance on multiple downstream tasks, exceeding or approaching the best algorithms in traditional deep learning, while also perform well on out-of-domain data or tasks; for adaptability, large models can utilize small amounts of data for fine-tuning and then adapt flexibly to new tasks or domains.
Depending on the modalities of data processing, existing large models can be classified into three categories: Large Language Models (LLMs) that process textual data, Visual Large Models (VLMs) that tackle visual data such as images and videos, and Multimodal Large Models (MLMs) that can handle both textual and visual multimodal data simultaneously.
1.1. Large language models
Large Models initially referred to large language models, whose development has been long and complex. With the success of the Transformer architecture, BERT [1] proposes the self-supervised task of mask prediction, achieving excellent performance on several natural language processing tasks through a self-supervised pre- training and fine-tuning paradigm. Concurrently, OpenAI introduces the GPT (Generative Pre-trained Transformer) series [2], which adopts the Transformer Decoder architecture and uses token-by-token generation for pre-training. These models achieved good generalization performance by increasing the number of parameters to hundreds of millions or billions and adding more training data. Following this, T5 [3] presents the Encoder-Decoder pre-training architecture, unifying the inputs and outputs of different natural language processing tasks by adding sentence prefixes. Inspired by these approaches, various pre-training and architectural variants have subsequently arisen, including Flan-T5 [4] and LlaMA [5] internationally, as well as Baichuan [6] and InternLM [7] in China.
In terms of large language model fine-tuning, prompt- based fine-tuning enables zero-shot capability for various natural language processing tasks by adding answer prompts for questions and inducing the model to output the corresponding results. Instruction-tuning builds an instruction-output data structure at the data level, allowing the model to understand the corresponding instruction after fine-tuning and exhibit good instruction generalization ability. Building on this, OpenAI proposes alignment-tuning, which uses human preferences as rewards and employs reinforcement learning to fine-tune the model, aligning the model's output with human preferences. Chain-of-Thought, on the other hand, assists the model in predicting more accurate results by decomposing a complex task into multiple simple tasks. To reduce the training effort associated with fine-tuning, sparse methods are often used to minimize the number of parameters needing adjustment; e.g., LoRA [8] utilizes a low-rank approximation to reduce the parameters during fine-tuning. Additionally, to address hallucination and real-time knowledge issues in large language models, the Retrieval-Augmented Generation (RAG) technique constructs external databases, enabling large language models to retrieve relevant content from databases when generating content, thus producing more accurate answers.
1.2. Large vision models
The pre-training of large vision models is similar to large language models, typically adopting two mainstream self-supervised methods: Contrastive Learning and Masked Autoencoders, such as EVA [9] and DINOv2 [10]. Based on these large vision models, we can achieve good performance on specific datasets and tasks through fine-tuning.
At the pre-training level, in addition to simple fine- tuning, models such as SAM [11] design a data-closed-loop process and use a large amount of partially labeled data for fine-tuning to achieve high performance on specific tasks or domains.
At the architectural level, researchers have explored different model architectures to unify the visual representation for various tasks, similar to large language models. There are two main approaches. The first approach designs a unified decoding head, represented by pix2seq [12], which transforms the output format of all tasks into tokens and solves different recognition tasks through token prediction. The second approach involves prompt learning, where the model predicts results for input based on prompt samples, such as SegGPT [13].
1.3. Multimodal large models
Multimodal large models generally comprise multiple unimodal large models by aligning and fine-tuning. For pre-training, CLIP [14] adopts an image-text multimodal alignment pre-training paradigm. Building on this, models such as ALIGN [15], LiT [16], and EVA-CLIP [17] further expand the training data and parameters to achieve better performance. Additionally, Image-Bind [18] and 3D- LLM [19] have been proposed to align more modal features, including speech, video, and 3D point cloud data.
In multimodal fine-tuning for vision tasks, generative models such as Diffusion Models [20] and World Models [21] fine-tune pre-trained large language models as generative prompts to guide the generated content. In perceptual tasks, VisionLLM [22] introduces a large language model as task guidance based on the unified vision architecture pix2seq, integrating its features into the image space to achieve excellent detection performance. Additionally, based on SAM, Open-Vocabulary SAM [23] combines SAM with CLIP to enable SAM to output object categories. GLEE [24] uses the feature output by the large language model as a prompt for SAM to guide segmentation results.
In multimodal fine-tuning for language tasks, LLaVA [25] and MiniGPT [26] use adapters to align the features of pre-trained vision models with linguistic features, enabling large language models to output content from images. CogVLM [27] and SPHINX [28] further fine-tune the decoder part of large language models like pix2seq, allowing the fine-tuned visual-language multimodal models to perform both text generation and vision tasks (including detection and segmentation). Additionally, SayCan [29] and the RT [30] series consider multimodal large models as brains of Embodied AI, fine-tuning them to directly output corresponding actions by giving a task description and image.
2. Application of large models in vertical industries
Large models can be categorized based on their design purpose, training data, and application scenarios into general foundation models, industry-specific foundation models, and scenario-specific models. General foundation models (L0 level) are designed to provide broad knowledge and capabilities without being tailored to any particular industry or task. These models are trained on large-scale, diverse datasets and can be applied to various tasks and fields, such as text generation, language understanding, and basic image recognition. Industry-specific foundation models are trained on data from particular industries to capture specialized knowledge and specific tasks within that domain. These models cater to the unique needs of sectors like healthcare, financial services, law, and manufacturing, offering more precise and efficient services. Based on the characteristics of the industry, they can be further subdivided. For instance, in the oil and gas sector, these models can be further subdivided into L1 and L2 levels based on industry-specific requirements. Both general and industry-specific foundation models are large-scale pre-trained models typically used as backbone networks for pre-training purposes. Scenario-specific models (L3 level) are created by further fine-tuning and customizing general or industry-specific foundation models to meet the demands of specific scenarios.
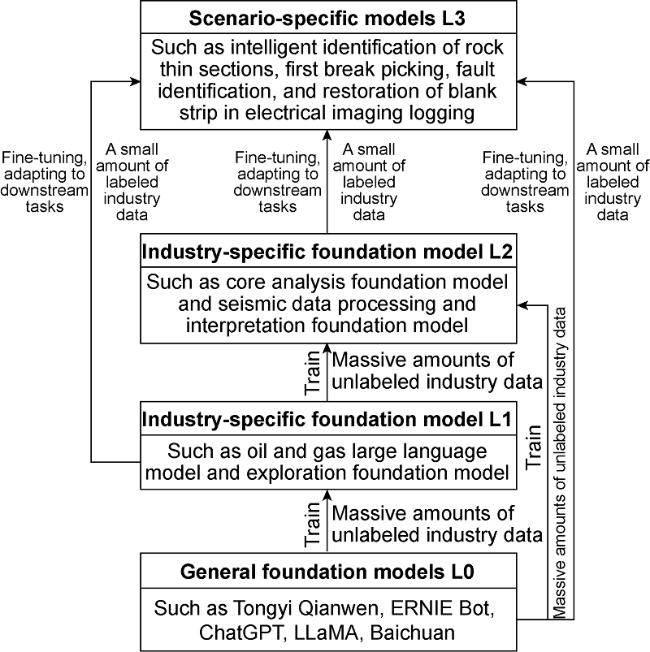
Fig. 1. Schematic diagram of classification of large models in the oil and gas industry. |
2.1. Large models in general industries
Currently, large model technology is being integrated into multiple industries, driving transformative developments. This paper provides a brief analysis of the application status of large models in several rapidly evolving fields, including autonomous driving, law, medicine, finance, transportation, and cybersecurity.
2.1.1. Autonomous driving
In the autonomous driving field, large models accelerate technological advancements and provide strong support for autonomous driving technology, especially in the capabilities of perception and scene understanding, decision-making, and simulation.
For perception and scene understanding, CAVG [31] combines multiple multimodal large models and fine-tune them with autonomous driving datasets, enabling functions like image-text dialogue and grounding in driving scenarios. ELM [32] integrates BERT, EVA, and Flan-T5, employing low-rank adaptation (LoRA) techniques for fine-tuning with autonomous driving data, achieving scene description, object grounding, event memory, and prediction.
For decision-making, the prevalent approaches among current methodologies involve utilizing general large language models as the foundational architecture. Subsequently, these models are refined with data specific to the autonomous driving domain, thereby yielding a large- scale model capable of making decisions for autonomous vehicles. Examples include GPT-Driver [33], LanguageMPC [34] and DriveVLM [35], which utilize the results of perception model and images as inputs to LLMs, formatting inputs and outputs to better convert LLM outputs into driving decisions. DILU [36] enhances this framework with a memory module, allowing the LLM to record driving experiences, improving reasoning and decision-making. LMDrive [37] and DriveGPT4 [38] are designed to integrate images and decision sequences directly into the large language model as tokens, thereby generating decision outcomes (Action) and realizing an end-to-end operational capability. Furthermore, DriveLM [39] has developed a Graph Visual Question Answering framework that emulates human cognitive processes. This system utilizes a multi-turn question-and-answer approach to incrementally arrive at decision-making conclusions.
In simulation, large models are primarily used to build world models for autonomous driving, predicting future frame images or point cloud data. For example, GAIA-1 and ADriver-I [40] utilize current image and decision data as inputs, transforming them into tokens via large language models coupled with visual models, which are subsequently processed by diffusion models to generate future frame images. DriveDreamer [41] adopts a two-phase training strategy: the initial phase involves the use of high-precision maps, object bounding boxes, and textual data as inputs, with the CLIP model acting as the encoder and a diffusion model as the generator to synthesize corresponding driving scene images; the second phase refines the initial model by incorporating historical decision data as conditional inputs to predict future frames. DriveDreamer-2 [42] diverges from its predecessor by eschewing the prior such as high-precision maps, object bounding boxes, and historical decisions as inputs, instead leveraging text instructions in large language models to generate high-precision overhead views and object bounding boxes, and further elaborate multi-view videos. Drive-WM [43] adopts variational autoencoder architecture, generating intermediate views from adjacent perspectives, thereby partially resolving consistency challenges between multi- view and multi-frame video data. GenAD [44] assembles a comprehensive autonomous driving video dataset through web crawling on YouTube and fine-tunes a pre-trained diffusion model on this dataset, enabling the concurrent prediction of future video frames and decision outcomes. Waabi Inc. [45] utilizes a pre-trained codebook model (Codebook) as the encoding objective for a variational autoencoder, integrating diffusion models with volumetric rendering to produce future frame point clouds. In a similar vein, OccWorld [46] employs a variational autoencoder for the encoding and decoding of occupancy tokens, yet it uniquely generates tokens sequentially in a fashion akin to the GPT architecture.
2.1.2. Law
Within the legal domain, large language models that have been pre-trained on legal knowledge data are instrumental in automating the comprehension of legal cases and statutes, thereby providing professional, intelligent, and comprehensive legal information and services to both laypersons and legal practitioners. A collaborative effort by Zhejiang University, DAMO Academy, and UniDt has led to the development of the wisdomInterrogatory legal large model [47], which builds upon the Baichuan-7B pre-trained model with secondary pre-training on legal knowledge data and instruction fine-tuning. This model is capable of generating legal documents and answering questions related to legal services. Alibaba Cloud’s Tongyi Farui [48] offers legal intelligent dialogue systems that can autonomously synthesize legal claims from case descriptions and draft legal documents, in addition to facilitating legal knowledge search and legal text comprehension. LawGPT [49], built on the ChatGLM-6B [50] model, has been refined with a legal domain-specific dataset, which includes legal dialogues, question-and-answer datasets, and Chinese judicial examination questions, thereby enhancing the model’s basic semantic understanding in the legal domain and bolstering its capability to understand and enact legal content. Lawyer LLaMA [51] has undergone extensive pre-training on a large legal corpus and is subsequently fine-tuned using data collected from legal professional qualification exams and legal consultations via ChatGPT, thereby equipping the model with practical application proficiency. DISC-LawLLM [52] fine-tunes the Baichuan-13B model with the DISC-Law-SFT legal dataset and constructs the DISC-Law-Eval benchmark for evaluating legal language models. ChatLaw [53] has been developed in various iterations to meet diverse legal service requirements, including ChatLaw-13B, ChatLaw-33B, and ChatLaw-Text2Vec. ChatLaw-13B is derived from fine-tuning the Ziya-LLaMA-13B-v1 model. ChatLaw-33B is trained on the Anima-33B model, further improving its logical reasoning abilities. ChatLaw-Text2Vec is a similarity-matching model fine-tuned on a dataset of judicial cases using BERT, designed to match users’ queries with relevant legal provisions. For the assembly of the training dataset, ChatLaw employs an extensive collection of raw textual materials, including legal news articles, legal forum discussions, legal provisions, judicial interpretations, legal consultations, judicial examination questions, and judicial decision texts, to fabricate a corpus of dialogic data.
2.1.3. Medicine
In the medical field, large models are applied across various scenarios, such as patient services, healthcare services, and medical research. These applications not only reduce costs in the healthcare industry but also improve the quality and efficiency of medical services. Wang et al. [54] have disclosed a Chinese large language model, IvyGPT, tailored for the medical domain. This model was developed through a process of training and fine-tuning that incorporated high-quality medical question-and- answer instances along with reinforcement learning from human feedback, thereby augmenting the model’s proficiency in particular medical contexts. Expanding on this foundation, Wang et al. [55] have advanced the development of CareGPT, which integrates numerous publicly accessible medical fine-tuning datasets with medical large language models. Med-PaL [56], derived from FLAN-PaLM, a variant of pre-trained natural language processing models, has been fine-tuned with open-source medical datasets to create specialized models for the medical field. ChatDoctor [57] fine-tunes LLaMA using information on over 700 diseases, including symptoms, medical tests, and medications, along with over 200 000 dialogue data entries sourced from online medical consultation websites, thereby enhancing the model’s application in the medical domain and improving its reliability by incorporating data from Wikipedia and medical databases. DoctorGLM [58] has been crafted by fine-tuning the ChatGLM-6B model with a Chinese medical dialogue dataset, yielding notable application outcomes.
2.1.4. Finance
In the financial sector, specialized financial large models play significant roles in activities such as sentiment analysis of news articles, algorithmic trading, risk assessment, and fraud detection. These models assist in making informed investment decisions and managing financial risks. Fudan University [59] has developed a large model tailored for the financial domain, named DISC-FinLLM. This model has been refined through the creation of a high-caliber financial dataset, DISC-Fin-SFT, followed by instruction-based fine-tuning of a general- domain Chinese large model. As a result, DISC-FinLLM is equipped with the competencies of a financial consultant, document analyzer, financial accountant, and current affair analyzer.
2.1.5. Transportation
In the field of transportation, leveraging the collaborative and interactive properties of large models, along with features like system coordination and automated content generation, can enhance the efficiency and convenience of traffic management. LLMLight [60] is a domain-specific large model designed for traffic signal control tasks. By integrating a large language model as an intelligent agent, it utilizes its advanced summarization capabilities to achieve traffic signal management.
2.1.6. Cybersecurity
The field of cybersecurity is also actively developing domain-specific large models to provide new tools and methods for protecting the Internet ecosystem and addressing the growing threats. Clouditera has open- sourced the cybersecurity large model, SecGPT [61], which serves as a foundational model for tasks such as vulnerability analysis, traceability analysis, and attack detection in cybersecurity.
2.2. Large models in the oil and gas industry
The utilization of large-scale models in the oil and gas industry is nascent, encompassing two main categories of specialized applications: those involving large language models and those centered around visual large models or multimodal large models.
2.2.1. Large language models in the oil and gas industry
Researchers both domestically and internationally are attempting to use general foundational models, pre- trained on massive corpora specific to the oil and gas industry, to develop large language models for this industry. Currently, large language models in the oil and gas industry are primarily applied in areas such as intelligent assistants and Q&A, data analysis and visualization. Exploratory research has also been conducted in specific subfields of oil and gas exploration and development.
2.2.1.1. Intelligent assistants and Q&A
In the realm of intelligent assistants and Q&A, large language models analyze vast amounts of industry data, research reports, and market trends to provide decision support for management and assist users in engineering tasks. These models enable users to query various industry knowledge and data through natural language, helping to solve technical issues encountered in their work. Scholars use both public and private datasets for incremental training to develop intelligent assistants and Q&A technologies based on large language models.
Some researchers have trained large language models using public datasets such as Wikipedia. For instance, PetroQA [62], presented at the 2023 Society of Petroleum Engineers Annual Technical Conference and Exhibition (SPE ATCE), and GeoGPT [63] developed by the Zhejiang Lab, are examples of this approach. Eckroth et al. [62] proposed a prototype tool named PetroQA that is designed to answer natural language questions, using content from Petrowiki to educate ChatGPT on petroleum industry knowledge, while also constraining it to avoid hallucinations and to cite sources of relevant knowledge. Additionally, they are developing and testing a new Q&A system called GraphQA, which allows users to search a knowledge base composed of facts and concepts related to wells, oil fields, and rock types, providing accurate answers specific to the petroleum industry. Marlot et al. [64] sought to enhance the efficiency and generalizability of natural language processing tasks in the oil and gas domain by employing an unsupervised multi-task learning method to train their large language models. They constructed a comprehensive dataset by gathering 33 000 documents, integrating external knowledge sources like Wikipedia with internal proprietary domain knowledge such as glossaries and technical documents. These documents encompass a wealth of information pertinent to the oil and gas industry, including articles, definitions, question-answer pairs, and technical details. Additionally, the researchers utilized the publicly accessible Arxivdata dataset from the earth sciences domain to extract summaries of academic articles. This collection formed the benchmark dataset for the training and evaluation of their models. Furthermore, they fine-tuned the GPT-2 base network for specific oil and gas domain question-answer pairs, providing actual word definitions for acronyms and explanations of domain-specific terms. The study found that even a smaller large model appropriately fine-tuned on specific domain data outperforms large models trained on general corpora. This research demonstrates that high-performance oil and gas domain language models can still be constructed through the careful selection of diverse datasets, even when resources are limited.
Some scholars have incorporated private datasets for incremental training on top of public datasets. In 2022, UNESP proposed the PetroBERT [65], a large model for the oil and gas sector based on the BERT model, which utilizes a Portuguese oil and gas domain artifact repository and a private daily drilling report corpus. The model was fine-tuned on the vertical domain private dataset for two tasks: named entity recognition and sentence classification, showing potential in both. In 2023, the research team at ExxonMobil introduced the customLLM model [66], reasoning that while foundational language models contain broad world knowledge, they exhibit biases toward non-industrial language. By introducing domain-specific tokens, they improved performance on specialized tasks. The pre-training corpus included proprietary resources such as equipment manuals, work orders, and maintenance data, as well as public resources like Wikipedia data, and explanations of relevant physical and chemical terms. To enhance the learning capabilities of customLLM, the team integrated external knowledge from Wikipedia, focusing on materials used, basic equipment information, and the oil and gas industry-related concepts, covering important physical and chemical principles to empower the model with industry knowledge. For model training, customLLM adopted a chunking strategy for the masked language model (MLM) training, fully utilizing the data during pre-training and applying data overlap between chunks to ensure narrative flow and continuity. Subsequently, the model was fine-tuned using clustering and text generation tasks to enhance its understanding of domain-specific data, thereby improving natural language comprehension. Kumar et al. [67] utilized a large language model with over 100 billion parameters. They fine-tuned the model and employed various prompt engineering strategies to complete text-processing tasks such as entity recognition, information extraction, and summarization. This model was applied to the vast amounts of unstructured text data generated by drilling activities in the oil and gas sector, overcoming difficulties in its review and interpretation.
2.2.1.2. Data analysis and visualization
In data analysis and visualization, large models assist in tasks such as generating business intelligence (BI) reports and performing data analysis.
The analysis of BI reports assisted by large models is a typical application of large models in data analysis and visualization. Some enterprises and scholars use Text2SQL (Text to Structured Query Language) technology to convert natural language text into structured query language (SQL), enabling large model-assisted report querying, analysis, and presentation. The oil and gas industry generates vast amounts of data from various sources, such as seismic surveys, logging logs, and drilling reports, stored in relational or non-relational databases. However, searching for relevant data records requires users to be familiar with database query syntax and schema definitions, which is challenging. Some scholars [68] have proposed a new framework for interacting with O&G databases using natural language: a text-to-text transformer (T5) trained in a multitask setting to convert natural language into SQL (Text-to-SQL) as the primary task, with query context classification and paragraph context classification as auxiliary tasks. They also introduced a data augmentation method for converting SQL to natural language (SQL-to-Text) and implemented query disambiguation and spell correction based on string and phoneme similarity algorithms. Singh et al. [69] proposed using large language models to build conversational AI chatbots, which can be trained to answer questions related to drilling and production monitoring, query datasets, perform diagnostic analysis, and generate rec-ommendations to improve operations. Using Text2SQL and similar technologies, users can quickly query and analyze historical report data through text or voice conversations.
In the domain of data analysis, the primary application lies in the utilization of large language models for real-time data querying and comprehensive analysis. Yi et al. [70] proposed the consolidating a vast amount of data from oil well construction operations into a common database. This dataset was then subjected to appropriate preprocessing and uploaded to a cloud platform for learning the generative pre-trained transformer. Subsequently, the learned model was integrated into the data platform to assist personnel in swiftly retrieving data. At the 2024 LEAP, Saudi Aramco announced the Aramco Metabrain, a large language model for the oil and gas industry with 250 billion parameters [71]. This model was trained using 7 trillion data points, encompassing over 90 years of historical data from Saudi Aramco. It can analyze drilling plans, geological data, historical drilling times, and costs, and recommend the most optimal well plans. Additionally, the model can provide precise forecasts for refined oil products, including price trends, market dynamics, and geopolitical insights.
2.2.1.3. Application in specific areas
The integration of large language models with oil and gas exploration and development operations is a primary direction for large language model development, and researchers have begun exploring this area.
In reservoir characterization, some researchers [72] have combined statistical methods and machine learning to study rock type classification schemes for carbonate reservoirs. They have applied models like GPT-4 to geological text descriptions to extract valuable geological parameters from unstructured text, facilitating rock type classification and permeability prediction in subsurface reservoirs. The combination of natural language processing (NLP) technologies, Q&A models, and semi-supervised sequence labeling provides a comprehensive and efficient solution for geological data analysis.
In geological modeling, creating accurate geological models in oil and gas engineering is crucial for simulating reservoir fluid flow, predicting production performance, and optimizing production strategies. Accurate geological models are essential for successful reservoir management. However, building these models often involves complex mathematical and physical models, such as full waveform inversion (FWI) techniques, which provide precise estimates of subsurface properties. Large language models, particularly ChatGPT, have demonstrated strong analytical capabilities. To apply models like ChatGPT to geological modeling in oil and gas engineering, Ogundare et al. [73] used a chain-of-thought approach [74] to guide ChatGPT in generating continuity equations and momentum equations. They then applied finite difference methods to discretize these equations, resulting in promising modeling solutions. However, ChatGPT still has limitations, such as frequently providing biased non-trivial solutions during actual calculations.
In numerical simulation, the oil and gas reservoir prediction often relies on numerical simulation methods. However, these simulations are typically high in computational cost and time-consuming. With the advancement of machine learning, machine learning-based numerical simulation methods have been applied to oil and gas reservoir predictions. As large model technology has emerged, some researchers have proposed a foundational model for oil and gas reservoir prediction [75]. This model uses many simulation variables, which enhances its data transferability in numerical simulation studies.
In predictive maintenance, some researches focus on leveraging the Internet of Things (IoT), artificial intelligence (AI), and machine learning, particularly large language models, to enhance predictive maintenance capabilities in oil and gas refineries. Predictive maintenance collects data via wireless sensors and uses machine learning algorithms to analyze equipment status, enabling quick and informed decision-making and significantly improving operational efficiency. As the demand for predictive maintenance grows, traditional methods face challenges, while new technologies like cloud computing and generative AI provide fresh impetus to the industry. Saboo et al. [76] introduced new solutions, such as Amazon Monitron, which combine wireless sensors with machine learning cloud services to achieve precise monitoring and predictive maintenance, thereby reducing unplanned downtime. Generative AI offers maintenance suggestions quickly through natural language chat interfaces, extending equipment lifespan and reducing maintenance costs. However, financial constraints and the complexity of technology integration remain obstacles to industry development.
2.2.2. Visual large models/multimodal models in the oil and gas industry
In contrast to large language models, visual large models and multimodal large models are endowed with robust image processing and analytical prowess. They excel in extracting key information from a spectrum of images/videos, including core images, geophysical images, imaging logging images, and remote sensing images, thereby conferring a broader array of applications within the oil and gas domain. Presently, scholars both domestically and internationally have embarked on exploratory research into the application of visual large models and multimodal large models within the oil and gas domain, with a primary emphasis on tasks related to oil and gas exploration, production management, and control.
In oil and gas exploration, the FalconCore team at the PetroChina Research Institute of Petroleum Exploration and Development (RIPED) has fine-tuned the SAM model on annotated rock images, such as thin sections, scanning electron microscope (SEM) images, and computed tomography (CT), to develop a large model for rock image instance segmentation. This model supports FalconCore's intelligent thin-section identification and SEM pore- throat analysis work [77⇓-79]. The team also fine-tuned a model based on LLaMA to create an intelligent repair model for electrical imaging logging images [80], which significantly outperforms traditional repair algorithms like Filtsim in cases with large blank stripe proportions. Zhang Dongxiao’s research team has developed the RockGPT [81], which employs a conditional generative model to reconstruct three-dimensional digital representations of rock from a single two-dimensional slice. This approach enables the acquisition of a three-dimensional digital porous structure, facilitating the investigation of pore-scale flow within oil reservoirs or underground aquifers. Sheng et al. [82] collected a large volume of seismic data and pre-trained a seismic foundation model (SFM) based on Transformer through self-supervised learning. The trained foundation model can be applied to downstream tasks such as seismic facies classification, seismic geobody segmentation, and inversion. In the oil and gas domain, SFM enables more efficient and accurate analysis of large seismic datasets, facilitating the extraction of key features to improve reservoir exploration accuracy and optimize drilling decisions. Zhang et al. [83] tackled the problem of lithology identification by preprocessing 400 m of continuous core images and creating a training dataset consisting of hundreds of thousands to millions of samples. This enabled the identification of 24 types of lithologies. They also proposed a centimeter-level identification scheme based on the Multiscale Vision Transformer (MVIT-V2) and other large model architectures. Traditional semantic segmentation models rely heavily on large annotated datasets, especially for complex CT and SEM rock images. SAM, however, has a certain degree of zero-shot segmentation capability and meets the high-precision segmentation needs in reservoir modeling, which is crucial for digital rock physics research with limited data and complex image features [84]. RockSAM [85] has solved the zero-shot digital rock image segmentation problem by fine-tuning the SAM. Specifically, when applied to digital rock images, the SAM model exhibited certain limitations in segmentation results due to its low feature contrast. To resolve this issue, RockSAM fine-tuned the SAM model, creating a variant that improved the segmentation accuracy of digital rock images without sacrificing its zero-shot learning capability. This adjustment ensures the effectiveness of RockSAM, providing a valuable tool for digital rock image analysis. Furthermore, RockSAM demonstrates significant efficiency in generating high-quality segmentation masks, overcoming the need for complex annotated data. With minimal human intervention and data, it learns and adapts, not only improving the accuracy of digital rock image analysis but also indicating the successful application of foundation models in the oil and gas industry.
In terms of oil and gas production control, the RIPED, in collaboration with the Digital Intelligent Technology Branch of the PetroChina Southwest Oil and Gasfield Company, fine-tuned the multimodal large model CLIP to adapt it for downstream tasks in change detection. This effort culminated in the development of a drone-based model for monitoring geological hazards along oil and gas pipelines. Wu et al. [86] proposed a composite oil spill detection framework, SAM-OIL, based on SAM. This framework consists of an object detector (such as Yolov8), SAM, and an Ordered Mask Fusion (OMF) module. Yolov8 is used to obtain the categories and bounding boxes of oil spill-related objects, then the bounding boxes are input into the adjusted SAM to retrieve category-independent masks, and finally, the OMF module is used to fuse the masks and categories. This framework can be used for marine oil spill detection tasks, enabling timely detection of spills and aiding in remediation. Liu et al. [87] proposed a precise automatic water leakage segmentation method based on SAM using adaptive techniques. This method can be applied to shield tunnel leakage detection tasks in the oil and gas sector, improving detection efficiency and reliability, thereby simplifying tunnel maintenance.
3. Challenges in the application of large models in the oil and gas industry
Data, computing power and algorithm are the core elements affecting the development of large model. Large model training is a very complex system engineering, which is reflected in the following three aspects. (1) The amount of data required for training is large: it requires a large amount of high-quality training data to improve the accuracy and generalization ability of the large model. (2) High requirements for computing power and algorithms: the number of parameters of large models usually reaches billions to tens of billions, and massive training is required to adjust these parameters, therefore strong computing power and optimization algorithms are needed to accelerate the training process. (3) Long training time: large model training takes days, weeks or even longer, and long training makes debugging and optimization process difficult. Table 1 shows the amount of data, computing power and training time used in the training of several typical large models. For example, the LLaMA-1 (65 B) model uses 1.4 TB tokens of pre-training data, the hardware resources are 2048 A100s with 80 GB of video memory, and the training time is 21 d; the PanGu-∑ (1 085 B) model uses 329 B tokens of pre- training data, the hardware resources are 512 Ascend 910, and the training time is 100 d.
Table 1. Data, computing power, and training time of typical large models [88] |
| Large model mode | Large model name | Size/B | Base model | Pre-train data scale | Hardware (GPUs/TPUs) | Training time |
|---|---|---|---|---|---|---|
| Open source | T5 | 11 | 1 TB tokens | 1024 TPU v3 | ||
| mT5 | 13 | 1 TB tokens | ||||
| PanGu-α | 13 | 1.1 TB | 2048 Ascend 910 | |||
| CPM-2 | 198 | 2.6 TB | ||||
| T0 | 11 | T5 | 512 TPU v3 | 27 h | ||
| GPT-NeoX-20B | 20 | 825 GB | 96 40G A100 | |||
| CodeGen | 16 | 577 B tokens | ||||
| Tk-Instruct | 11 | T5 | 256 TPU v3 | 4 h | ||
| UL2 | 20 | 1 TB tokens | 512 TPU v4 | |||
| OPT | 175 | 180 B tokens | 992 80G A100 | |||
| BLOOM | 176 | 366 B | 384 80G A100 | 105 d | ||
| GLM | 130 | 400 B tokens | 768 40G A100 | 60 d | ||
| OPT-IML | 175 | OPT | 128 40G A100 | |||
| LLaMA-1 | 65 | 1.4 TB tokens | 2048 80G A100 | 21 d | ||
| Closed source | GShard | 600 | 1 TB tokens | 2048 TPU v3 | 4 d | |
| GPT-3 | 175 | 300 B tokens | ||||
| LaMDA | 137 | 2.81 TB tokens | 1024 TPU v3 | 57.7 d | ||
| HyperCLOVA | 82 | 300 B tokens | 1024 A100 | 13.4 d | ||
| ERNIE 3.0 | 10 | 375 B tokens | 384 V100 | |||
| FLAN | 137 | LaMDA | 128 TPU v3 | 60 h | ||
| MT-NLG | 530 | 270 B tokens | 4480 80G A100 | |||
| Yuan 1.0 | 245 | 180 B tokens | 2128 GPU | |||
| Gopher | 280 | 300 B tokens | 4096 TPU v3 | 920 h | ||
| ERNIE 3.0 Titan | 260 | 300 B tokens | 2048 V100 | 28 d | ||
| GLaM | 1 200 | 280 B tokens | 1024 TPU v4 | 574 h | ||
| AlphaCode | 41 | 967 B tokens | ||||
| PaLM | 540 | 780 B tokens | 6144 TPU v4 | |||
| AlexaTM | 20 | 1.3 TB tokens | 128 A100 | 120 d | ||
| U-PaLM | 540 | PaLM | 512 TPU v4 | 5 d | ||
| Flan-PaLM | 540 | PaLM | 512 TPU v4 | 37 d | ||
| PanGu-Σ | 1 085 | PanGu-α | 329 B tokens | 512 Ascend 910 | 100 d |
The oil and gas industry has the characteristics of long chain, wide range of business and strong professionalism. Compared with traditional industries, the oil and gas industry shows some particularities in the development of industry large models. The data of the oil and gas industry is complex and heterogeneous, involving data from multiple stages, such as geological exploration, drilling, production, transportation, and so on. Large models are required to be able to handle highly complex and heterogeneous data sets. The oil and gas industry uses intensive professional knowledge, involving geology, reservoir engineering, chemical engineering, and other disciplines. Therefore, large models need to incorporate plentiful knowledge graphs to ensure the accuracy and reliability of the model output. Given these particularities, the application of AI large models in the oil and gas industry faces many challenges and problems.
(1) The current quantity and quality of data cannot support the training of large models. Most of the data in the oil and gas industry comes from underground, which is multi-solvable and unverifiable. The data sample is small, and it is difficult to obtain label data. At the same time, large models need to learn massive amounts of data, but the oil and gas industry has high requirements for data security and confidentiality, and generally faces the problem of "isolated data island". Therefore, how to integrate the data and train the basic model of the industry on the premise of ensuring that the industry data does not go on public cloud and does not leak has become a key challenge for the application of large models in the industry.
(2) High R&D investment cost. Large models usually require a large amount of computing resources and data for training and optimization, which often requires a considerable investment cost. Training a basic model for seismic processing and interpretation with 10×108 parameters requires an estimated 1 TB of seismic data of various types, and the total number of 4×4 sized tokens to be created is about 105×104, with a total computing power requirement of about 840×1012 Flops (Floating Point Operations per Second). At present, some companies of the Chinese oil and gas industry have the computing power for fine-tuning basic models, but generally do not have the computing power for training industry basic models. At the same time, due to the purchase restriction policy of NVIDIA GPU (Graphics Processing Unit) and the gap between the domestic and foreign chip industries, it is difficult for the domestic oil and gas industry to build the computing power required for large models in a short term. Meanwhile, domestic chips are incompatible with mainstream frameworks such as CUDA (Compute Unified Device Architecture) used by large models, resulting in some large model algorithms being unable to adapt to domestic chips. In addition to computing power investment, large model training will also incur high operating costs such as electricity and network fees and high R&D investment.
(3) It is difficult for the oil and gas industry to achieve autonomous control of large model algorithms. Compared with algorithms such as deep learning, large models have a higher threshold. The current round of large model development is largely driven by a small number of high-end algorithm talents. Among the large models of the oil and gas industry that have been released in China, some are assembled and packaged, and face the possibility of copyright disputes and the inability to change the core algorithm. Existing large model algorithms can be divided into open-source and closed-source algorithms. Open-source algorithms have high transparency and flexibility, and the oil and gas industry can conduct further research and development based on open-source algorithms according to business needs. However, open- source algorithms may lack the necessary technical support and security guarantees, which may lead to the risk of leaking trade secrets. The capabilities of open-source algorithms are also far lower than closed source algorithms. Currently, the large open-source algorithm models with good reputation in the industry are basically at the level of GPT3.5, including LLaMA-2, Mistral 8x7B, ChatGLM-6B, and GLM-130B. In addition, many open- source algorithms have many restrictive clauses in the copyright agreement, which also causes the oil and gas industry to face copyright disputes when developing based on open-source algorithms. If a closed-source algorithm is used, it will be difficult to achieve autonomous control of the core algorithm.
(4) In the domestic oil and gas industry, there is a phenomenon of "blindly following the trend" in the application of large models. The large model research and development in China shows the phenomenon of "hundred-model war", which interferes with the development strategy of large models in the oil and gas industry to a certain extent. There are now more than 100 large models in China, and several large language models have been released in the oil and gas industry in just one year. However, Shell, Chevron, bp, Total, Schlumberger, Halliburton and other foreign companies have yet to release industry large models.
(5) The concept of large model in the oil and gas industry is mixed up. Large AI models refer to deep learning models with hundreds of millions or even trillions of parameters, such as language models and image recognition models with Transformer architecture. The core is to learn complex patterns and internalize knowledge through training with massive data. The models commonly used in the oil and gas industry are complex geological models. These models are built based on multidisciplinary data such as geophysics, geology, and reservoir engineering, and are designed to simulate and predict the distribution, structure, and fluid behavior of underground oil and gas reservoirs. Such models play an important role in guiding the exploration and deployment of oil and gas fields, the design of development plans, and production optimization. Their "bigness" is more reflected in the complexity of the model and the vast geographical space it covers, rather than the magnitude of the parameters.
4. Prospect of large model application in the oil and gas industry
Although the application of large models in the oil and gas industry faces many challenges, it still needs to be accelerated. To develop large models in the oil and gas industry, we first must fully understand large models. Large models are not omnipotent, and a single model cannot solve all problems in oil and gas exploration and development. It is not expected that large models will surpass or replace traditional deep learning in all domains. To establish models for specific oil and gas analysis applications, it should be guided by business needs and focus on solving specific problems. Based on gradual accumulation, we will be able to develop a large model that meets various application needs.
(1) When applying large models in the oil and gas industry, we should always focus on the needs of the primary business, with the core of solving practical problems and creating business value, and should avoid falling into the technical competition of general basic models. The core concept of large models (especially pre-trained large models) is to train a powerful basic model through a small number of people, and then a wide range of user groups can fine-tune it in their own specific tasks or scenarios with only a small number of labeled samples, and finally obtain a model with fairly good performance. The application of large models in the oil and gas industry should focus on fine-tuning and adapting to downstream tasks. It is not suitable for the development of L0-level general foundation models. It is recommended to independently develop L3-level scenario models and some L2-level industry-specific foundation models with good data quality to ensure the autonomy and controllability of the technology stack. For L1-level industry-specific foundation models and some L2-level industry-specific foundation models with large data volume, long training time, and high computing power requirements, it is recommended to build industry-specific foundation models with the help of external computing power and algorithms under the premise of ensuring data security, and fully demonstrate the feasibility from the aspects of data quality, computing power support, input-output, etc. For example, for large language models, several large language models for the oil and gas industry have been launched domestically and abroad. The oil and gas industry should adhere to the principle of optimal resource allocation and focus on the main business of oil and gas. Carefully consider the input cost, output benefit, technology maturity and stability, industry focus, and core competitiveness, and fully demonstrate whether to independently build a large language model.
(2) The oil and gas industry can take the application of large models as an opportunity to strengthen data management throughout the entire life cycle and improve data governance capabilities. First, it is necessary to strengthen data quality control from the source of data collection, and to ensure automatic and standardized data collection through a combination of software and hardware. Secondly, improve data quality through data cleaning, data fusion and matching, data integrity enhancement, etc. Then, organize experts to label data, build a label sample library required for large model training, and strictly control the labeling quality. Meanwhile, introduce industry priori knowledge constraints for data enhancement, federated learning, and small sample-zero sample learning to develop downstream models suitable for targeted scenario applications. Finally, strengthen data security and privacy protection through data desensitization, data encryption, access control and auditing, compliance review, etc. The Chinese data used by OpenAI to train large models comes from the Internet and is general data. The data quality is better than that of the oil and gas industry, but a lot of work has been done to improve data quality. The first basic work to be done in the application of large models in the oil and gas industry is to improve data quality and build high-quality data sets and label sample libraries required for large model applications. The prosperity and development of general industry large models is largely benefited from open-source data sets such as ImageNet. Therefore, under the premise of ensuring data security and industry privacy, a batch of high-quality open-source data sets should be constructed to promote the construction of a large model R&D ecosystem in the oil and gas industry.
(3) Taking the oil and gas big model as an opportunity to promote the construction of integrated computing power. The construction method can adopt a hybrid mode combining leasing and self-construction. Enterprises should choose the way of obtaining computing power according to their own business needs, cost budget and technical strength. For routine computing tasks, it can be quickly responded by leasing public cloud resources; for tasks involving sensitive data or requiring long-term stable operation, self-building or co-building data centers should be considered to ensure data security and sustainable supply of computing power. Consider overall planning for the construction of general computing, intelligent computing, and supercomputing facilities, and highlight the construction of integrated computing facilities focusing on intelligent computing. General computing should meet the basic computing needs of daily operations, intellectual computing better focuses on the efficient execution of intelligent algorithms such as deep learning and machine learning, and supercomputing targets on large-scale scientific computing and complex simulations.
(4) Take the application of large models as an opportunity to strengthen the "artificial intelligence + energy" interdisciplinary team building, and promote the autonomy and control of large model technology stack. The development strategy of foreign general foundation model is "large Internet enterprises + startups" mode, such as Microsoft and OpenAI, Google and DeepMind, Amazon and Anthropic, etc. Compared with the "hundred-model war" in China, the development of the abroad large model industry is more rational and pays more attention to the construction of a joint R&D ecosystem. Large model is an emerging technology based on big data, strong computing power and advanced algorithms. The application of large models in the oil and gas industry should not be "single-handed", but should build a joint R&D ecosystem with IT companies, universities, etc. Collaborations and exchanges in large model algorithms and other aspects should be strengthened through project cooperation, talent training, and co-construction of R&D platforms. Mutual goals and division of labor should also be clarified, as well as the systems and norms such as intellectual property allocation and management, data confidentiality and privacy protection, to ensure a healthy, orderly and efficient operation of the ecology and to promote in-depth application and innovative development of large models in the oil and gas industry.
5. Application examples
The large models possess the capability for comprehensive analysis of multimodal data. By using large model technology, it is promising to conduct integrated analyses of multimodal data such as core descriptions, logging curves, and seismic images. In the short term, scenarios with good data foundation and some background in deep learning can be selected to further enhance the generalization and universality of existing models through pre-training foundation models or fine-tuning based on general foundation models. In the future, various models can be cascaded, using cores as benchmarks, to achieve integrated analysis of core, well logging, and seismic data by using multimodal large models. Following the principle of step-by-step training, single models should be trained individually first, then cascaded them to gradually construct reservoir-scale large models.
This article illustrates the application process and methods of recent large models through two examples. The first example uses the construction method of a foundation model for seismic data processing and interpretation as an illustration. Sheng et al. [82] proposed the construction method of Seismic Foundation Model (SFM), as shown in Fig. 2 . The first step is data collection, utilizing various seismic datasets collected from 192 global 3D seismic surveys. The second step is data preparation, where 2 286 422 2D seismic lines were meticulously selected from the collected datasets. A pre-training dataset was constructed through a self- supervised training strategy using a large amount of unlabeled seismic data, and data quality was enhanced through cleaning and balanced distribution. The third step is to construct the pre-trained foundation model. Based on the characteristics of geophysical data, unsupervised generative learning combined with a Transformer architecture was selected for training. Considering computational costs and training time, the Masked Autoencoders (MAE) method was chosen to train the seismic foundation model. On the basis of the SFM, using a small amount of labeled data to adapt to downstream tasks such as classification and segmentation, models for scenarios like seismic facies classification and first break picking can be developed. Experimental results show that the performance of fine-tunned model based on SFM is significantly better than other traditional deep learning models.
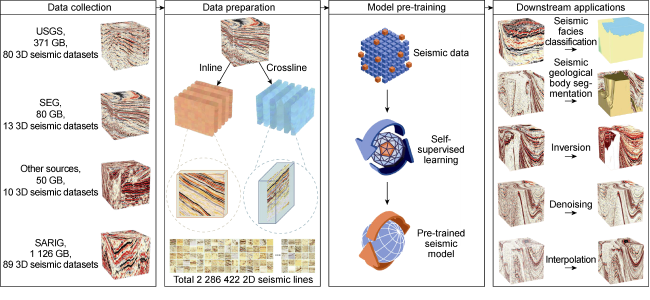
Fig. 2. SFM model construction and application [82]. |
The second example illustrates the fine-tuning methods and applications of large models using the intelligent analysis of core images. Our team has conducted exploratory research in two aspects. One aspect is the rock image segmentation technology based on the open-source visual large model SAM. Instance segmentation is a commonly used technique in intelligent analysis of rock images. Traditional deep learning methods require constructing different models for different data types, resulting in poor generalization capabilities. As shown in Fig. 3 , our team fine-tuned the SAM model using labeled data from thin sections, electron microscopy, CT scans, and other rock images to construct a large model for rock image instance segmentation. This model performs well in segmenting various types of rock image data. This application example demonstrates the advantages of large models in terms of generalization and universality.
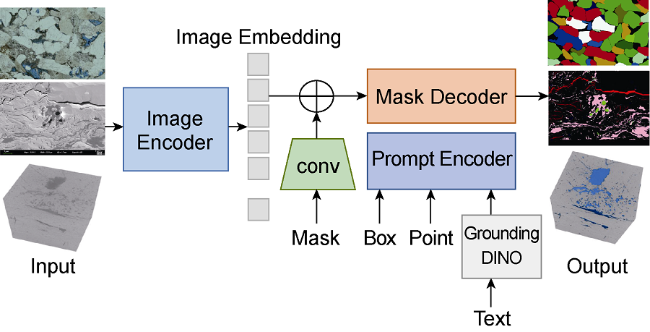
Fig. 3. Network architecture of large model for rock image instance segmentation based on SAM. |
On the other hand, the intelligent analysis of natural cross-section scanning electron microscope (SEM) images based on multimodal models exemplifies the emergent properties of large models. Currently, the analysis of natural cross-section SEM images remains at the stage of manual and qualitative analysis. The accuracy of the analysis results heavily depends on the skill level of the researchers, consuming substantial manpower while making it difficult to obtain quantitative statistical results. The human brain can directly comprehend the three-dimensional and multi-dimensional information inherent in natural cross-section images, but it is challenging to describe this information by using a few graphical parameters. Additionally, since it is impossible to accurately annotate the component contours in natural cross-section SEM images, traditional deep learning networks for image segmentation and object detection cannot achieve intelligent identification. The advent of large model technology offers the potential for intelligent analysis of natural cross-section SEM images.
Our team has proposed a natural cross-section SEM image intelligent analysis model called RockSE-Ferret, based on the multimodal large model Ferret. Considering that secondary electron SEM images of natural cross- sections have "micro-relief" characteristics, presenting a certain three-dimensional effect, it is challenging to determine the contour boundaries of pores and clay minerals, and to accurately annotate specific core structural features or precise locations of certain visual features. Additionally, regarding their occurrence states, clay minerals mainly appear in weathered and altered strata, exhibiting various forms such as filling, lining, and bridging. These forms include book-like, flaky, and filamentous shapes, sometimes appearing mixed and crossed, making it difficult to accurately distinguish them with detection frames. The multimodal large model Ferret, developed by Apple Inc., has shown outstanding performance in region-specific tasks, region localization tasks, and text-region combination tasks, making it suitable for the complex scene understanding required for natural cross-section SEM images. Therefore, our team chose Ferret as the foundation model to develop the RockSE-Ferret model for intelligent analysis of natural cross-section SEM images.
First, an instruction tuning dataset for core SEM imaging instructions, RockSE-GRIT, was constructed. This dataset includes annotations in five aspects: objects, relationships between objects, descriptions of specific regions, complex reasoning based on regions, and robustness. It also includes related question-and-answer pairs. The first three aspects were annotated by experts, while complex reasoning and related question-and-answer pairs were constructed using large language models such as ChatGLM3. Robustness was achieved by adding negative samples to the dataset.
Next, our team uses the professional domain instruction tuning dataset RockSE-GRIT fine-tuning model on the basic model Ferret. Through instruction fine-tuning, the model was enabled to understand and process SEM images and related textual descriptions, adapting to downstream tasks.
Finally, RockSE-Ferret, through scene understanding, achieved intelligent identification of the three-dimensional distribution of clay minerals, pores, and cracks, as well as the three-dimensional shapes of particles, as shown in Fig. 4 .

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Fig. 4. Intelligent analysis of natural cross-section SEM images based on the scene model RockSE-Ferret. |
6. Conclusions
In recent years, artificial intelligence technology has advanced from specialized applications with limited capabilities to a new era known as Artificial General Intelligence (AGI). This leap has been driven by the development of large models, which have gradually become a key force in driving the development of new quality productivity. The large model industry in China is currently facing a "hundred-model war" scenario. Compared to the United States, the core competitiveness of the large model industry in China lies in the integration of "large models + physical industries". The industry applications of large models show immense potential, but the technological pathways are still immature, and practical implementations face many difficulties and challenges. The application of large models in the oil and gas industry must be approached rationally, fully recognizing the unique characteristics of large models in this sector, and building a solid foundation in terms of data, computational power, and algorithms. The implementation of large models in the oil and gas industry should be carried out steadily, always guided by the needs of the oil and gas business, and avoiding following blind conformity.