Petroleum Exploration and Development, 2022, 49(2): 339-348 doi: 10.1016/S1876-3804(22)60028-4
An unsupervised clustering method for nuclear magnetic resonance transverse relaxation spectrums based on the Gaussian mixture model and its application
GE Xinmin1,2,3, XUE Zong’an,4,*, ZHOU Jun2,5, HU Falong6, LI Jiangtao7, ZHANG Hengrong8, WANG Shuolong9, NIU Shenyuan1, ZHAO Ji’er1
1. School of Geosciences, China University of Petroleum, Qingdao 266580, China
2. CNPC Key Well Logging Laboratory, Xi’an 710077, China
3. Laboratory for Marine Mineral Resources, Qingdao National Laboratory for Marine Science and Technology, Qingdao 266071, China
4. Oil and Gas Survey Center of China Geological Survey, Beijing 100083, China
5. China Petroleum Logging Co. Ltd., Xi’an 710077, China
6. PetroChina Research Institute of Petroleum Exploration & Development, Beijing 100083, China
7. PetroChina Qinghai Oilfield Company, Dunhuang 736202, China
8. Zhanjiang Branch of CNOOC Ltd., Zhanjiang 524057, China
9. Sinopec Research Institute of Petroleum Engineering, Beijing 100101, China
National Natural Science Foundation of China(42174142) National Science and Technology Major Project(2017ZX05039-002) Operation Fund of China National Petroleum Corporation Logging Key Laboratory(2021DQ20210107-11) Fundamental Research Funds for Central Universities(19CX02006A) Major Science and Technology Project of China National Petroleum Corporation(ZD2019-183-006)
Abstract
To make the quantitative results of nuclear magnetic resonance (NMR) transverse relaxation (T2) spectrums reflect the type and pore structure of reservoir more directly, an unsupervised clustering method was developed to obtain the quantitative pore structure information from the NMR T2 spectrums based on the Gaussian mixture model (GMM). Firstly, We conducted the principal component analysis on T2 spectrums in order to reduce the dimension data and the dependence of the original variables. Secondly, the dimension-reduced data was fitted using the GMM probability density function, and the model parameters and optimal clustering numbers were obtained according to the expectation-maximization algorithm and the change of the Akaike information criterion. Finally, the T2 spectrum features and pore structure types of different clustering groups were analyzed and compared with T2 geometric mean and T2 arithmetic mean. The effectiveness of the algorithm has been verified by numerical simulation and field NMR logging data. The research shows that the clustering results based on GMM method have good correlations with the shape and distribution of the T2 spectrum, pore structure, and petroleum productivity, providing a new means for quantitative identification of pore structure, reservoir grading, and oil and gas productivity evaluation.
GE Xinmin, XUE Zong’an, ZHOU Jun, HU Falong, LI Jiangtao, ZHANG Hengrong, WANG Shuolong, NIU Shenyuan, ZHAO Ji’er. An unsupervised clustering method for nuclear magnetic resonance transverse relaxation spectrums based on the Gaussian mixture model and its application. Petroleum Exploration and Development, 2022, 49(2): 339-348 doi:10.1016/S1876-3804(22)60028-4
Introduction
Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information.
Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24].
These methods provide new ideas for the interpretation of NMR logging data. However, there are some obvious drawbacks. Firstly, it is still difficult to describe the nonlinear response between pore structure and NMR response. Secondly, data manipulation and parameter setting should be calibrated with experimental results or manually. To this end, we propose a novel method to process NMR logging data based on the Gaussian mixture model (GMM). It is an unsupervised technique that the clustering result is objective. Both numerical simulation and field NMR logging data have been used to demonstrate the method.
1. Principle of GMM-based clustering
The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3).
The purpose of the GMM clustering is to solve the mean, variance, and weight for each Gaussian basis function, which is usually achieved by the expectation maximization (EM) algorithm. The basic idea of the EM algorithm is to maximize the likelihood function for problems with latent variables and some iteration equations [26,31⇓ -33]. It is often using the logarithmic form of the likelihood function (Eq. (4)), in order to simplify the computation. Therefore, the problem is then transformed to find the maximal value of the logarithmic form of the likelihood function, which is expressed by Eq. (5).
$\theta \left( X \right)=\ln \underset{i=1}{\overset{M}{\mathop{\prod }}}\,p\left( {{X}_{i}}|M,D,W \right)$
The EM algorithm can be separated into two steps. The first step obtains the expectation value (E step) and the second step obtains the maximum value (M step). The specific iterative procedures are as follows: (1) Initialize the model parameters, let the mean Mk as a random matrix, the variance matrix Dk as an identity matrix, and the weight matrix Wk as the prior probability for each model. (2) Obtain the prior probability belonging to each Gaussian model at each depth (or measured point), which can be expressed as Eq. (6). (3) Update the model parameters using the prior probability and Eq. (7) to Eq. (9). (4) Repeat Step 2 and Step 3 until satisfying the convergence criteria of Eq. (10).
$|\theta {{\left( X \right)}_{j}}-\theta {{\left( X \right)}_{j-1}}|<\varepsilon $
Determination of the optimal number of the Gaussian models is imperative to this algorithm. If the number is too large, it is easy to cause the overfitting. However, if the number is too small, it is easy to reduce the flexibility of fitting new data. The frequently used method to over these drawbacks is to introduce the Akaike information criterion (AIC). Based on the information entropy, the AIC can help us to choose the models with the minimum information loss [34⇓⇓-37], which is expressed in Eq. (11).
$AIC=-2\ln (L)+2p$
The AIC is the basis of determining the optimal number of the Gaussian models. Moreover, sometimes the AIC is monotonically decreased with the number of the Gaussian models. Therefore, it is practical to use the variation of the AIC for the optimal number, increasing the sensitivity between the AIC and the optimal number of the Gaussian models to some extent [38].
We adopt the variation of the AIC to quantify the optimal number of the Gaussian models, which is expressed in Eq. (12). If the variation of the AIC is too large when increasing the number of the Gaussian models from p to p+1, it is inferred that p is not enough to depict the original dataset. Otherwise, the clustering results are similar for p and p+1. We can choose p as the optimal number from the perspective of computation cost, and the corresponding variation of the AIC will reach its minimum value.
2. Numerical simulation of GMM clustering for T2 spectrums
As is stated above, T2 spectrums are the coupled responses of many petrophysical properties such as pore structure and fluid components. The T2 spectrum measured at each depth follows Gaussian distribution and indicates the distribution of relaxation components. We can use the GMM algorithm to process T2 spectrums and obtain unsupervised clustering results, which will be used for pore structure evaluation and reservoir classification.
Before the GMM clustering, it is necessary to compress the big NMR data by principal component analysis (PCA) to reduce the relevance between the data and enhance the computation efficiency. In doing so, firstly, we should evaluate the adaptability and effectiveness of the GMM clustering method through numerical simulation, and then generalize the method to process raw NMR logging data.
2.1. Dimension reduction of T2 spectrums by PCA
T2 spectrums can be viewed as a matrix that is composed of the amplitudes of different relaxation times, and the column (or the dimension) of the matrix is dependent on the number of inversion points. The amplitudes corresponding to different relaxation times have certain correlations. To reduce the redundant information in the T2 spectrums and highlight the analyzable factors, we used PCA algorithm to compress the high dimension data to low dimension and extract the most representative principal components [38-39].
Assuming the number of inversion points is L and the number of measured points is M, T2 spectrums can be expressed as an observation matrix, seen in Eq. (13). Since the column vectors corresponding to different relaxation times have certain correlations, it is feasible to transform the observation matrix to a new matrix with a few linearly uncorrelated columns that contain the largest amount of information, and to improve the computation efficiency by PCA. The original observation matrix can be converted by Eq. (14) and Eq. (15).
The basic principle and the computation method of the PCA algorithm can be seen in references [38⇓-40]. The specific steps are as follows: (1) Normalize the raw data; (2) Calculate the correlation matrix to obtain the eigenvectors and the eigenvalues; (3) Compute the cumulative variance contribution rate according to the distribution of eigenvalues; (4) Set the cut-off value of contribution rate and extract the principal component signal.
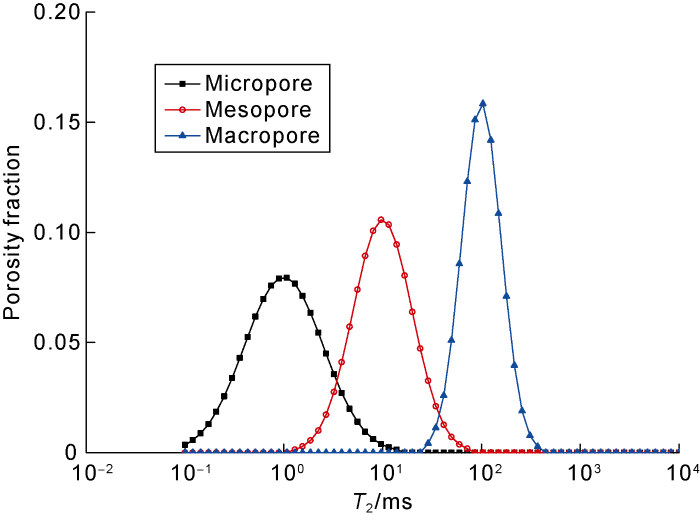
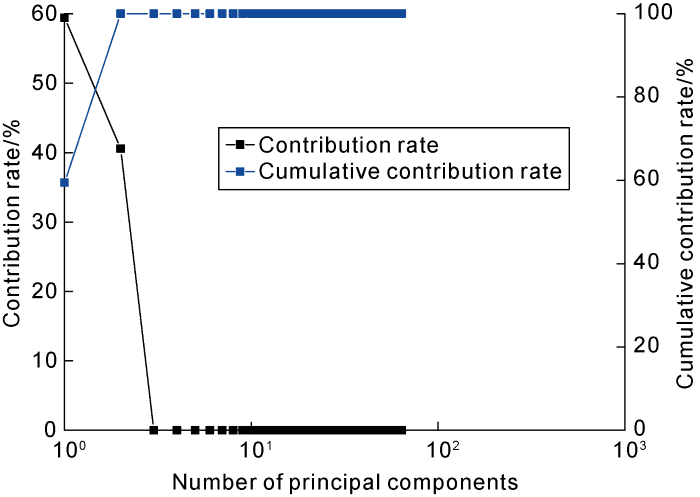
We used three log Gaussian functions to simulate 400 groups of T2 spectrums (Fig. 1). The purpose of these log Gaussian functions is to control the peak value and the distribution range. In our forward model, the peak values are 1, 10, and 100 ms, the variances are 0.4, 0.3, and 0.2. Moreover, the relaxation time is defined from 0.1 ms to 10000 ms with 64 logarithmic uniform grids. The amplitudes of T2 spectrums are generated randomly and then normalized to reduce the influence of the porosity. When pore fluid is water, the T2 spectrums can represent micropores, mesopores and macropores. The statistical results show that the relaxation time of the micropore ranges from 0.1 ms to 14 ms, the relaxation time of the mesopore ranges from 1.3 ms to 86 ms, and the relaxation time of the macropore ranges from 24 ms to 372 ms. Fig. 2 shows the relationship between the number of principal components and the contribution rate, and the cumulative contribution rate. It is observed that the cumulative contribution rate can reach as high as 99.95% when the number of principal components is 2, indicating that there is a high correlation between the column vectors (or amplitudes) corresponding to different relaxation times. It only needs to choose the first two principal components for the GMM clustering algorithm.
Fig. 2.
The contribution rate and cumulative value of forward simulated T2 spectrums.
2.2. Determination of optimal clustering number and result analysis
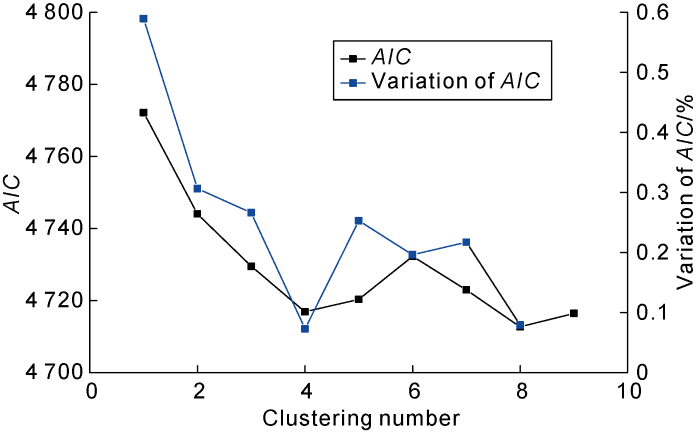
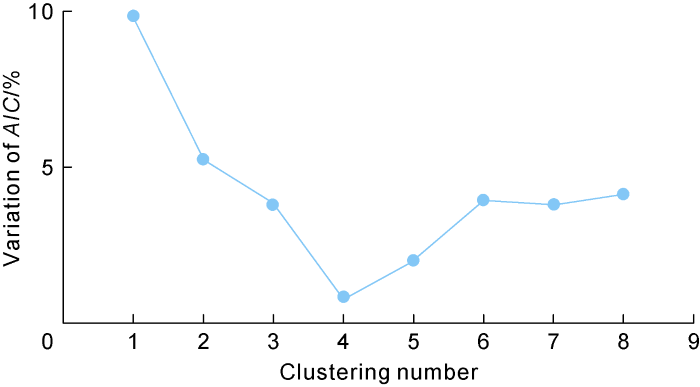
After dimension reduction by PCA, we used the first two principal components as the input data to conduct the GMM clustering driven by the EM algorithm. In the computation, the iteration threshold was 0.01, the maximum iteration number was 10 000, and the maximal clustering number (or the number of the Gaussian models) was 9. Fig. 3 shows the AIC and the variation of the AIC at different clustering numbers. It is seen that the variation of the AIC has reached its minimal value (0.073%) when the clustering number is 4, revealing the optimal fitting result has been fulfilled. Considering the fitting accuracy and computation cost, we chose 4 as the optimal clustering number.
Fig. 3.
AIC and variation of AIC at different clustering numbers.
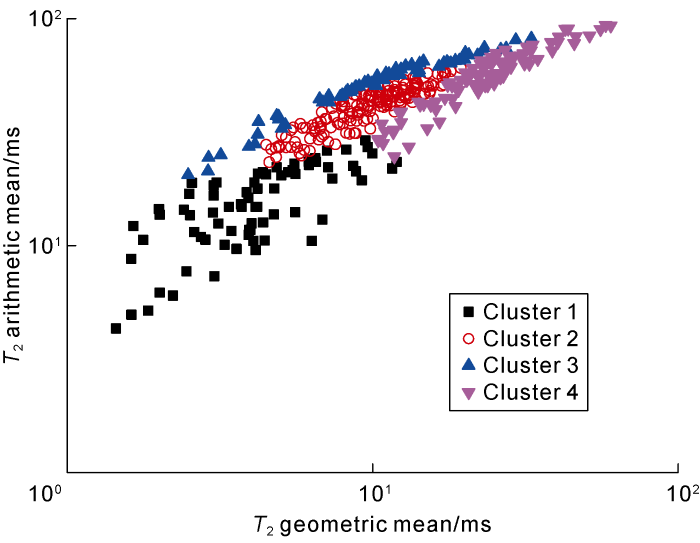
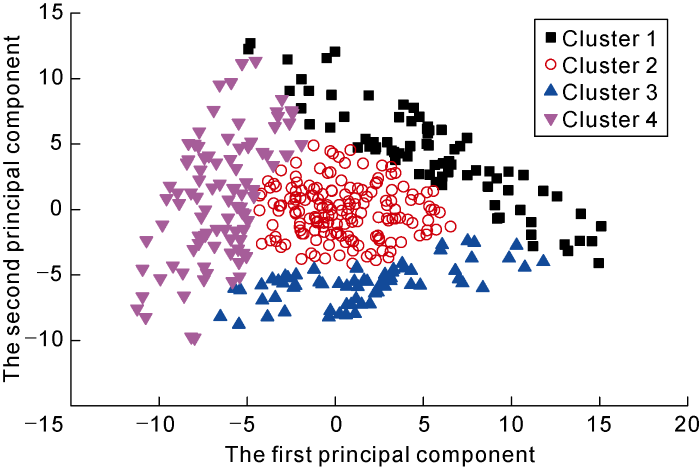
We computed the T2 geometric mean and the T2 arithmetic mean of these four clusters and obtained their crossplot, as shown in Fig. 4. It is obvious that both the T2 geometric mean and the T2 arithmetic mean are increased with from Cluster 1 to Cluster 4. However, they are less distinct from Cluster 2 to Cluster 4, indicating that it is difficult to classify the clusters simply using the conventional T2 average value or conventional crossplot.
Fig. 4.
Crossplot of T2 geometric mean and T2 arithmetic mean of 4 clusters.
Fig. 5 shows the crossplot of the first and the second principal components for all clusters. Compared with Fig. 4, the distinction is more obvious, further verifying the reasonability of the clustering results based on the GMM clustering algorithm.
Fig. 5.
Crossplot of the first and the second principal components of 4 clusters.
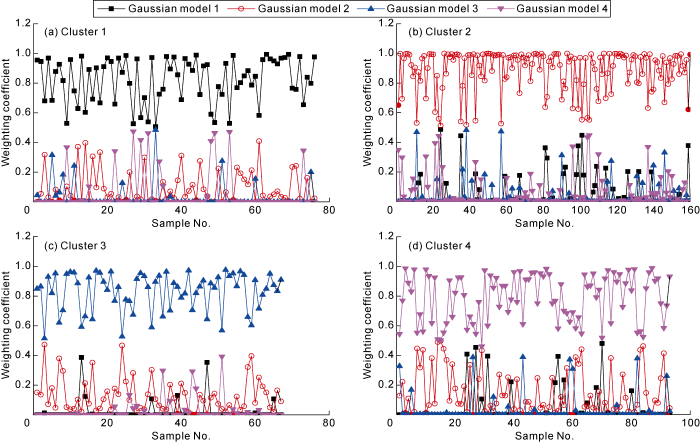
Fig. 6 displays the distribution of the weighting coefficients of the Gaussian models corresponding to four clusters. It is seen that the weighting coefficients correspond well with the clusters. Through the GMM clustering algorithm, we can get the clustering results, can assign the membership of the clusters precisely based on the probability distribution. The GMM clustering algorithm provides flexible cluster shape and the probability of the data belonging to different clusters. It can avoid hard classification effectively and bring more information than the hard-clustering algorithms [30].
Fig. 6.
The weighting coefficients of 4 Gaussian models corresponding to four clusters.
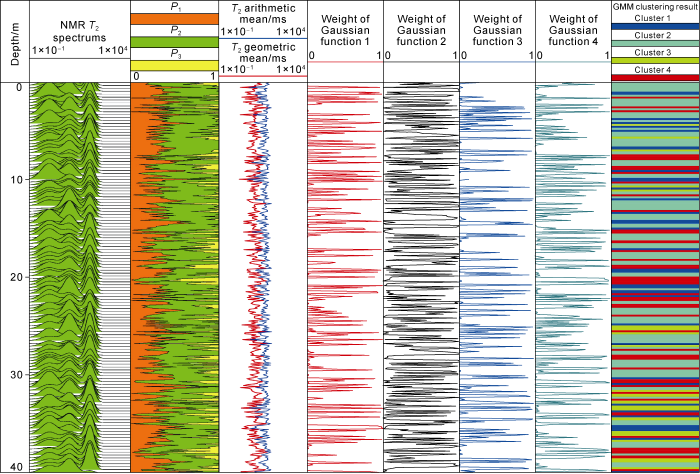
Integrating the above algorithms, we processed the numerical simulated NMR logging data and obtained the following results (Fig. 7). Compared with conventional NMR logging interpretation profiles, our method can provide quantitative GMM clustering results and the probability distribution of different clusters, which give intuitive information.
Fig. 7.
The GMM clustering result and interpretation profile for simulated T2 spectrums.
3. GMM clustering result for NMR T2 spectrums
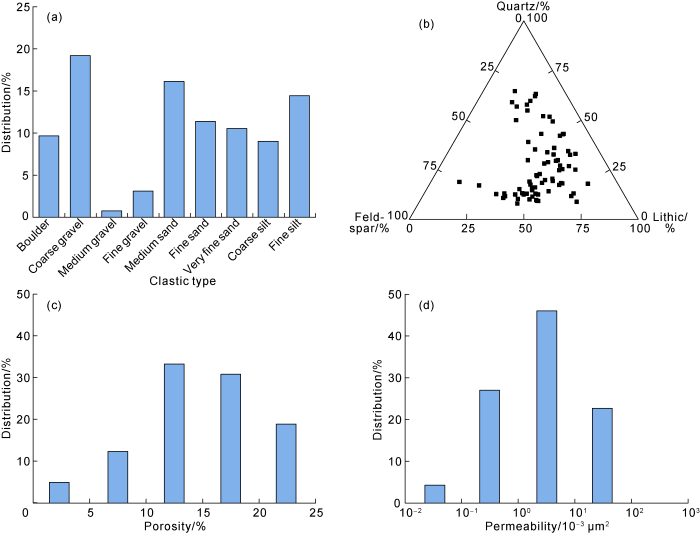
The Niudong area is located in the eastern front of Altun mountain in the northwest Qaidam Basin. The Jurassic formation in the Niudong area is typical braided delta plain sediment which is mainly composed of medium to coarse sandstones including feldspathic lithic sandstone or lithic arkose filled with kaolinite and calcite at a low content (Fig. 8). The reservoir space is mainly composed of secondary pores, followed by intergranular pores, which are uniformly distributed and well connected. The reservoir physical properties are relative good: the porosity is from 5% to 20%, and 11.3% on average; and the permeability is (0.1-100.0)×10-3 μm2, and 5×10-3 μm2 on average (Fig. 8).
Fig. 8.
Lithology and reservoir physical properties of the Jurassic formation in Niudong area, Qaidam Basin.
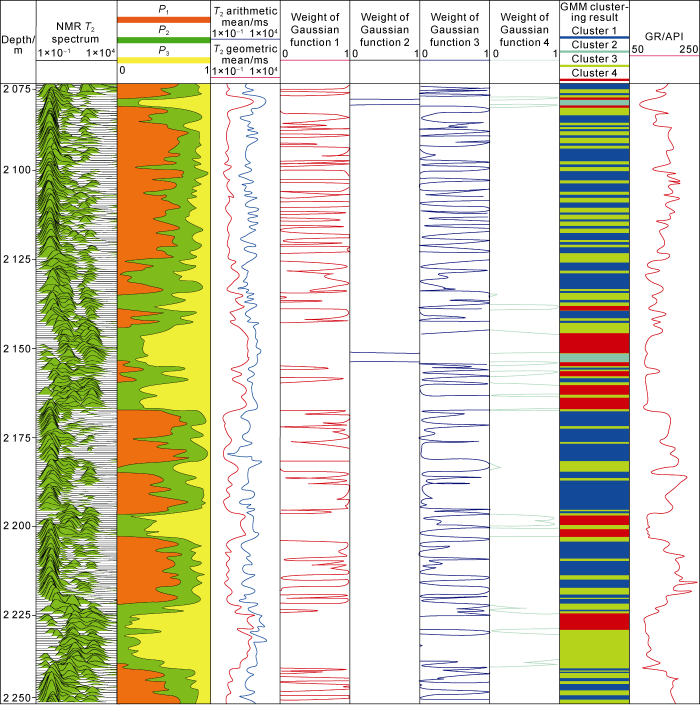
Using the D9TW model, NMR logging data were acquired in Well XX-1 well using a MRIL-P logging tool manufactured by Halliburton. We obtained the standard T2 spectrums from the data acquired with long waiting time (12.988 s) and short echo spacing (0.9 ms). Setting the threshold of the cumulative contribution rate as 90%, we compressed the observation matrix of 64 columns to 7 principal components by PCA. Using the GMM clustering algorithm to these 7 principal components, we obtained the relationship between the variation of the AIC and the number of the Gaussian models (Fig. 9). Finally, we fixed the optimal cluster number to be 4 according to the criteria mentioned above. Applying 0.3, 10 and 100 ms as cut-off values, we obtained the proportions of the amplitude in the relaxation range of 0.3 to 10 ms (namely P1), the relaxation range of 10 to 100 ms (namely P2), and the relaxation range higher than 100 ms (namely P3) (Fig. 10).
Fig. 10.
The GMM clustering result and interpretation profile for NMR logging T2 spectrums of the Jurassic formation in Well XX-1.
Fig. 11 shows the proportions of the amplitude for 4 relaxation ranges agree well with the clustering results. Cluster 1 has the maximal P1 and the minimal P3, indicating the development of micropores. Cluster 2 has the maximal P3 and the minimal P1, indicating the development of macropores. Clustering 3 has the complicated distribution of the relaxation components. Cluster 4 has similar distribution as Cluster 2.
Fig. 11.
Proportions of the amplitude of different relaxation time ranges for four clusters.
Three intervals were tested in the Jurassic formation drilled in Well XX-1. From the section from 2074.5 m to 2082.5 m, open-flow gas production at 2422 m3/d was obtained through a 6-mm nozzle after fracturing stimulation. It is a low-yield gas layer belonging to Cluster 3 according to the GMM clustering algorithm. From the section from 2146.5 m to 2153.5 m, open-flow gas production at 132 942 m3/d and open-flow oil production at 13.27 t/d were obtained through a 10-mm nozzle. It’s a high-yield gas layer belonging to Cluster 4. From the section from 2228.5 m to 2240.5 m, open-flow gas production at 22 484 m3/d and open-flow oil production at 0.42 t/d were obtained through a 5-mm nozzle. It is a high-yield gas layer belonging to Cluster 4. Observed on typical thin sections from drilled cores in the section from 2228.5 m to 2240.5 m (Fig. 12), the grain size is relatively large and the lithology is mainly particle-supported (gravelly) giant to coarse-grained feldspathic lithic sandstone. The particles are subangular and contact each other point to point. The cementation type is mostly pore cementation. The quartz surface is clean and observed wavy extinction. The feldspar is strongly weathered. The pores are mainly intergranular dissolved pores, intragranular dissolved pores and matrix micropores. In addition, the shale interval from 2096 m to 2103 m (showing high GR readings) belongs to Cluster 1.
Fig. 12.
Typical thin sections of a tested interval from 2228.5 m to 2240.5 m, Jurassic formation in Well XX-1. (a) Gravelly feldspathic lithic sandstone; coarse-extremely coarse, less filled, porous; 2230.07 m. (b) Lithic sandstone; extremely coarse, less filled, porous; 2231.10 m. (c) Lithic sandstone; extremely coarse, less filled, porous; 2233.69 m. (d) Lithic arkose; argillaceous and inequigranular, filled with argillaceous and calcite cements, less porous; 2236.08 m.
4. Conclusions
We proposed a quantitative method to get unsupervised clustering results of NMR logging T2 spectrums using the GMM clustering algorithm. To improve the computational efficiency, we compressed the NMR T2 data using the PCA method before clustering. Moreover, we adopted the AIC criteria and the variation of the AIC to determine the optimal number of the Gaussian models and the clusters, which can enhance the validity of the clustering results. The method we proposed has been verified by both numerical simulation and field NMR logging data. The result shows that the clustering results agree well with the pore structure, reservoir type and production capacity of the reservoir analyzed. And the quantitative characterization results can directly reflect the reservoir type and pore structure.
It should be noted that the influences of fluid properties were not considered in our numerical simulation. Real NMR response and its T2 spectrum are affected by various factors such as lithology, fluid and pore structure, which should be considered in future studies. Moreover, if the GMM clustering algorithm is used after typing lithology or constrained by other information such as petrophysical, well test and production data, the clustering result and its reasonability may be improved to some extent.
Nomenclature
AIC—Akaike information criterion;
d—physical dimension of well logging data;
Dk—variance matrix of the k-th Gaussian basis function;
i—sequence number of well logging data;
j—number of iteration;
k—sequence number of Gaussian basis functions;
L—point number on T2 spectrum of NMR logging;
M—sample number of well logging data;
Mk—mean matrix of the k-th Gaussian basis function;
N—total number of Gaussian basis functions;
p—cluster number;
p(X)—total probability density function;
Wk—weight matrix of the k-th Gaussian basis function;
X—matrix of well logging data;
Y—component matrix corresponding to logging data;
U—basis matrix corresponding to logging data;
θ(X)—logarithmic likelihood function;
θ(X)j—logarithmic likelihood function after the j-th iteration;
φ(X, Mk, Dk)—probability density function of the k-th Gaussian basis function;
ε—iteration threshold of logarithmic likelihood function;
Θ(X)—the maximum of logarithmic likelihood function.
Acknowledgements
This work is supported by CNPC Key Well Logging Laboratory. The NMR logging data and related geological data are supported by the Institute of Exploration and Development of PetroChina Qinghai Oilfield Company. We also thank Dr. Jianyu Liu from PetroChina Research Institute of Petroleum Exploration & Development (Northwest) for his valuable suggestions.
KAUSIKR, JIANGT M, VENKATARAMANANL, et al.Reservoir producibility index (RPI) based on 2D T1-T2 NMR logs. Texas, USA: SPWLA 60th Annual Logging Symposium, 2019.
Application of machine learning tool to separate overlapping fluid components on NMR T2 distributions: Case studies from laboratory displacement experiment and well logs
In clinic, intima and media thickness are the main indicators for evaluating the development of atherosclerosis. At present, these indicators are measured by professional doctors manually marking the boundaries of the inner and media on B-mode images, which is complicated, time-consuming and affected by many artificial factors. A grayscale threshold method based on Gaussian Mixture Model (GMM) clustering is therefore proposed to detect the intima and media thickness in carotid arteries from B-mode images in this paper. Firstly, the B-mode images are clustered based on the GMM, and the boundary between the intima and media of the vessel wall is then detected by the gray threshold method, and finally the thickness of the two is measured. Compared with the measurement technique using the gray threshold method directly, the clustering of B-mode images of carotid artery solves the problem of gray boundary blurring of inner and middle membrane, thereby improving the stability and detection accuracy of the gray threshold method. In the clinical trials of 120 healthy carotid arteries, means of 4 manual measurements obtained by two experts are used as reference values. Experimental results show that the normalized root mean square errors (NRMSEs) of the estimated intima and media thickness after GMM clustering were 0.104 7 ± 0.076 2 and 0.097 4 ± 0.068 3, respectively. Compared with the results of the direct gray threshold estimation, means of NRMSEs are reduced by 19.6% and 22.4%, respectively, which indicates that the proposed method has higher measurement accuracy. The standard deviations are reduced by 17.0% and 21.7%, respectively, which indicates that the proposed method has better stability. In summary, this method is helpful for early diagnosis and monitoring of vascular diseases, such as atherosclerosis.
ZHANGMeixia, LILi, YANGXiu, et al.
A load classification method based on Gaussian mixture model clustering and multi-dimensional scaling analysis
Joint inversion of T1-T2 spectrum combining the iterative truncated singular value decomposition and the parallel particle swarm optimization algorithms
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
... [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
2
2012
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
... ⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
2
2002
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
... -3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
Fluid identification method based on 2D diffusion-relaxation nuclear magnetic resonance (NMR)
1
2012
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
1
2018
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
In situ fluid typing and quantification with 1D and 2D NMR logging
1
2007
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
1
2019
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
First application of new generation NMR T1-T2 logging and interpretation in unconventional reservoirs in China
1
2020
... Nuclear magnetic resonance (NMR) logging data plays a very important role in obtaining reservoir parameters, pore structure and fluid types of complex and unconventional oil and gas reservoirs [1⇓-3]. Since relaxation signals are only related to the hydrogen atom in a porous medium, it is feasible to calculate the porosity, permeability, irreducible water saturation, pore radius, and the wettability index of the reservoir by measuring the signals of the macroscopic magnetization vector of the hydrogen atom decaying with time, and inverting them to T2 spectrums, and considering proper petrophysical models. Then the quality and pore structure of the reservoir can be evaluated by the inverted T2 spectrums [1⇓-3]. And finally, quantitative data such as the fluid types, fluid saturations and fluid viscosities will be obtained by using multidimensional data such as the longitudinal relaxation time, diffusion coefficient and internal magnetic gradient of the reservoir [4⇓⇓⇓-8]. Compared with conventional well logging data such as GR, AC, and compensated DEN, T2 spectrums include richer geological information. ...
Permeability evaluation of tight sandstone based on dual T2 cutoff values measured by NMR
1
2018
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Matrix method of transforming NMR T2 spectrum to pseudo capillary pressure curve
1
2015
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
The quantitative evaluation method of low permeable sandstone pore structure based on nuclear magnetic resonance (NMR) logging
1
2016
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Determination of nuclear magnetic resonance T 2 cutoff value based on multifractal theory: An application in sandstone with complex pore structure
1
2015
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Key parameters of water saturation based on concentration of T 2 spectrum distribution
1
2017
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Quantitative characterization of sandstone NMR T2 spectrum
1
2016
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Fractal characteristics of reservoir rock pore structure based on NMR T2 distribution
1
2007
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Reservoir pore structure classification technology of carbonate rock based on NMR T2 spectrum decomposition
1
2014
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
A decomposition method of nuclear magnetic resonance T2 spectrum for identifying fluid properties
1
2020
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Lithological control on gas hydrate saturation as revealed by signal classification of NMR logging data. Journal of Geophysical Research
1
2015
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Novel methodology for accurate resolution of fluid signatures from multi-dimensional NMR well-logging measurements
1
2017
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Application of machine learning tool to separate overlapping fluid components on NMR T2 distributions: Case studies from laboratory displacement experiment and well logs
1
2019
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Integration of NMR and conventional logs for vuggy facies classification in the Arbuckle Formation: A machine learning approach
1
2020
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Quantitative evaluation of shale pore structure using nuclear magnetic resonance data
1
2021
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
New evaluating method of oil saturation in Gulong shale based on NMR technique
1
2021
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Pore structure characterization and classification based on fractal theory and nuclear magnetic resonance logging
1
2021
... Limited by international technical support and field operating conditions, NMR logging data recorded in most oilfields in China are only one-dimensional T2 data. It is vital to make a great use of conventional T2 spectrums to solve the petroleum and geological problems. Many scholars conducted substantial investigations on the applications of NMR logging data and made great achievements on estimating porosity, permeability, irreducible water saturation, T2 cutoff value, as well as T2 calibration of pore size [9⇓⇓-12]. In addition, some innovative researches on interpretation of T2 spectrums were proposed, including pore structure indication based on the concentration of T2 spectrum distribution, quantitative T2 spectrum analysis based on mathematical morphology, multifractal analysis of T2 spectrums, key parameter extraction based on multi-Gaussian function fitting, as well as machine learning techniques such as self-organizing maps neural network, non-negative matrix factorization, and independent component analysis [13⇓⇓⇓⇓⇓⇓⇓⇓⇓⇓-24]. ...
Change detection in synthetic aperture radar images based on image fusion and Gaussian mixture model
1
2020
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
Detection of carotid intima and media thicknesses based on ultrasound B-mode images clustered with Gaussian mixture model
3
2020
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... [26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... The purpose of the GMM clustering is to solve the mean, variance, and weight for each Gaussian basis function, which is usually achieved by the expectation maximization (EM) algorithm. The basic idea of the EM algorithm is to maximize the likelihood function for problems with latent variables and some iteration equations [26,31⇓ -33]. It is often using the logarithmic form of the likelihood function (Eq. (4)), in order to simplify the computation. Therefore, the problem is then transformed to find the maximal value of the logarithmic form of the likelihood function, which is expressed by Eq. (5). ...
A load classification method based on Gaussian mixture model clustering and multi-dimensional scaling analysis
2
2020
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... ⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
Sea ice image segmentation with unsupervised clustering based on the Gaussian mixture model
2
2011
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... ⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
Application of the gradient-based Gaussian mixture model to spatial clustering of three-dimensional attribute field
2
2019
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... -29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
Extracting glacier information from remote sensing imageries by automatic threshold method of Gaussian mixture model
2
2021
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... Fig. 6 displays the distribution of the weighting coefficients of the Gaussian models corresponding to four clusters. It is seen that the weighting coefficients correspond well with the clusters. Through the GMM clustering algorithm, we can get the clustering results, can assign the membership of the clusters precisely based on the probability distribution. The GMM clustering algorithm provides flexible cluster shape and the probability of the data belonging to different clusters. It can avoid hard classification effectively and bring more information than the hard-clustering algorithms [30]. ...
A robust EM clustering algorithm for Gaussian mixture models
2
2012
... The GMM is the extension of univariate Gaussian distribution in high dimensional space. It is the linear combination of finite independent multivariate Gaussian distribution models. As a probability model with the fastest learning ability, it constructed an optimal mixed multidimensional Gaussian distribution model by fitting input dataset, so we can get unsupervised clustering results, consequently data distribution pattern, and classification scheme. The clustering method based on the GMM is widely used in many areas such as image segmentation, signal processing, biomedical science, and geosciences [25⇓⇓⇓⇓⇓-31]. According to the concept of the GMM[26⇓⇓-29], the probability distribution of a logging dataset can be expressed by Eq. (1) to Eq. (3). ...
... The purpose of the GMM clustering is to solve the mean, variance, and weight for each Gaussian basis function, which is usually achieved by the expectation maximization (EM) algorithm. The basic idea of the EM algorithm is to maximize the likelihood function for problems with latent variables and some iteration equations [26,31⇓ -33]. It is often using the logarithmic form of the likelihood function (Eq. (4)), in order to simplify the computation. Therefore, the problem is then transformed to find the maximal value of the logarithmic form of the likelihood function, which is expressed by Eq. (5). ...
Clusterability assessment for Gaussian mixture models
1
2015
... The purpose of the GMM clustering is to solve the mean, variance, and weight for each Gaussian basis function, which is usually achieved by the expectation maximization (EM) algorithm. The basic idea of the EM algorithm is to maximize the likelihood function for problems with latent variables and some iteration equations [26,31⇓ -33]. It is often using the logarithmic form of the likelihood function (Eq. (4)), in order to simplify the computation. Therefore, the problem is then transformed to find the maximal value of the logarithmic form of the likelihood function, which is expressed by Eq. (5). ...
Short-term power forecasting method of wind farm based on Gaussian mixture model clustering
1
2021
... The purpose of the GMM clustering is to solve the mean, variance, and weight for each Gaussian basis function, which is usually achieved by the expectation maximization (EM) algorithm. The basic idea of the EM algorithm is to maximize the likelihood function for problems with latent variables and some iteration equations [26,31⇓ -33]. It is often using the logarithmic form of the likelihood function (Eq. (4)), in order to simplify the computation. Therefore, the problem is then transformed to find the maximal value of the logarithmic form of the likelihood function, which is expressed by Eq. (5). ...
Identification of switched systems based on Gaussian mixture clustering
1
2021
... Determination of the optimal number of the Gaussian models is imperative to this algorithm. If the number is too large, it is easy to cause the overfitting. However, if the number is too small, it is easy to reduce the flexibility of fitting new data. The frequently used method to over these drawbacks is to introduce the Akaike information criterion (AIC). Based on the information entropy, the AIC can help us to choose the models with the minimum information loss [34⇓⇓-37], which is expressed in Eq. (11). ...
Investigation of the widely applicable Bayesian information criterion
1
2017
... Determination of the optimal number of the Gaussian models is imperative to this algorithm. If the number is too large, it is easy to cause the overfitting. However, if the number is too small, it is easy to reduce the flexibility of fitting new data. The frequently used method to over these drawbacks is to introduce the Akaike information criterion (AIC). Based on the information entropy, the AIC can help us to choose the models with the minimum information loss [34⇓⇓-37], which is expressed in Eq. (11). ...
Wind power output scene division based on Gaussian hybrid clustering
1
2021
... Determination of the optimal number of the Gaussian models is imperative to this algorithm. If the number is too large, it is easy to cause the overfitting. However, if the number is too small, it is easy to reduce the flexibility of fitting new data. The frequently used method to over these drawbacks is to introduce the Akaike information criterion (AIC). Based on the information entropy, the AIC can help us to choose the models with the minimum information loss [34⇓⇓-37], which is expressed in Eq. (11). ...
Joint inversion of T1-T2 spectrum combining the iterative truncated singular value decomposition and the parallel particle swarm optimization algorithms
1
2016
... Determination of the optimal number of the Gaussian models is imperative to this algorithm. If the number is too large, it is easy to cause the overfitting. However, if the number is too small, it is easy to reduce the flexibility of fitting new data. The frequently used method to over these drawbacks is to introduce the Akaike information criterion (AIC). Based on the information entropy, the AIC can help us to choose the models with the minimum information loss [34⇓⇓-37], which is expressed in Eq. (11). ...
Classification of refractory damage signals based on the principal component analysis and Gaussian mixture model
3
2014
... The AIC is the basis of determining the optimal number of the Gaussian models. Moreover, sometimes the AIC is monotonically decreased with the number of the Gaussian models. Therefore, it is practical to use the variation of the AIC for the optimal number, increasing the sensitivity between the AIC and the optimal number of the Gaussian models to some extent [38]. ...
... T2 spectrums can be viewed as a matrix that is composed of the amplitudes of different relaxation times, and the column (or the dimension) of the matrix is dependent on the number of inversion points. The amplitudes corresponding to different relaxation times have certain correlations. To reduce the redundant information in the T2 spectrums and highlight the analyzable factors, we used PCA algorithm to compress the high dimension data to low dimension and extract the most representative principal components [38-39]. ...
... The basic principle and the computation method of the PCA algorithm can be seen in references [38⇓-40]. The specific steps are as follows: (1) Normalize the raw data; (2) Calculate the correlation matrix to obtain the eigenvectors and the eigenvalues; (3) Compute the cumulative variance contribution rate according to the distribution of eigenvalues; (4) Set the cut-off value of contribution rate and extract the principal component signal. ...
A new porosity calculation method based on principal component analytical technology for altered formation
2
2012
... T2 spectrums can be viewed as a matrix that is composed of the amplitudes of different relaxation times, and the column (or the dimension) of the matrix is dependent on the number of inversion points. The amplitudes corresponding to different relaxation times have certain correlations. To reduce the redundant information in the T2 spectrums and highlight the analyzable factors, we used PCA algorithm to compress the high dimension data to low dimension and extract the most representative principal components [38-39]. ...
... The basic principle and the computation method of the PCA algorithm can be seen in references [38⇓-40]. The specific steps are as follows: (1) Normalize the raw data; (2) Calculate the correlation matrix to obtain the eigenvectors and the eigenvalues; (3) Compute the cumulative variance contribution rate according to the distribution of eigenvalues; (4) Set the cut-off value of contribution rate and extract the principal component signal. ...
Dynamic recognition method for water-flooded layer with discrete process neural network based on the principal component analysis
1
2010
... The basic principle and the computation method of the PCA algorithm can be seen in references [38⇓-40]. The specific steps are as follows: (1) Normalize the raw data; (2) Calculate the correlation matrix to obtain the eigenvectors and the eigenvalues; (3) Compute the cumulative variance contribution rate according to the distribution of eigenvalues; (4) Set the cut-off value of contribution rate and extract the principal component signal. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}