


Introduction
Artificial intelligent (AI) reservoir modeling is an emerging modeling technology and has been more and more widely used in the petroleum industry[1]. For reservoir simulation, AI-based modeling technology integrates reservoir engineering analytical techniques with artificial intelligence, machine learning, and data mining to formulate an empirical and spatiotemporally calibrated full field model[2,3]. According to the source of the spatiotemporal database, the AI-based reservoir modeling methods can be divided into two types: top-down modeling (TDM) and surrogate reservoir modeling (SRM). The TDM method uses field data such as well logs, cores, historical production data, well test data, and seismic attributes to build dynamic reservoir model [1,2,3,4,5,6,7]. The SRM method has spatiotemporal database from numerical reservoir simulation model[2].
Numerical simulation approaches reservoir simulation and modeling from bottom to top, while TDM approaches reservoir simulation and modeling from top to bottom to improve the accuracy of the model[3]. TDM has been achieving technical and commercial success in several North American, North Sea and Middle-Eastern oil fields[8,9]. Outcomes of TDM include oil production, GOR and WC of existing wells, as well as infill drilling locations optimization, optimal well production, remaining reserves assessment, and field development planning, so it can play a key role in major decision-making related to oilfield development[2,3]. TDM can also distinguish the changes in the production behavior due to operational issues from those due to reservoir characteristics[3,8], providing an efficient alternative model of fluid flow in the reservoir. Moreover, TDM uses pattern recognition of AI and data mining to develop a model, which can perform simulation, analysis, and forecast of oil and gas production. TDM utilizes fuzzy pattern recognition to identify high production regions and infill locations of a field in a given duration. Compared to numerical modeling, TDM and other AI-based reservoir modeling methods have the advantages of less computation time and resource consumption, and they heavily rely on available actual data and measurements.
Artificial neutral network (ANN) imitates the process of how a brain processes information to learn to perform specific tasks such as classification, clustering and regression. In contrast to most models driven by rule-based programs or probability, ANN is driven by data and is composed of many nodes (or neurons) that interact with each other. The Input Layer of ANN has multiple nodes, each representing a specific attribute or parameter of the model to predict the necessary output. The hidden layer that lies in between the input and out layers is composed of multiple artificial neurons that attempt to identify trends, patterns, and features.
The ANN workflow starts by assigning random weights to each input parameter to represent its influence. The computed weighted sum has to meet a threshold level that is defined by an activation function such as Sigmoid, Relu, Tanh for an acceptable output to be computed. A bias can be introduced into the activation function for the perceptron to meet the threshold. In this study, a bias of 1 was used. The assigned weights change continuously until the resulting combination meets the threshold. The weights were continuously adjusted in multiple training using the stochastic gradient descent learning algorithm, meanwhile, the error between the predicted output and the desired output was calculated by back-propagation algorithm to optimize the objective function[10].
In this study, TDM was used for a carbonate oil reservoir in the Middle East for the first time. The developed TDM in this study has multiple interconnected neural networks, each of them models a key dynamic parameter, and the output of a model is the input of the next model. The TDM modeling procedure is presented in this paper, and TDM modeling is used is to do analysis to optimize oilfield development plan.
1. Methodology
1.1. TDM development.
The essence of data-driven modeling is the deduction of the physical features from the representative data that is used to construct it. The TDM is calibrated (history matched) by using the wells available data. The overall approach of this study is to use the data to build a reservoir model, history match the reservoir model, and then use the history matched reservoir model for production forecast and reservoir management. In TDM workflow, the final spatio-temporal database goes through the input feature selection process for data-driven model development. An intelligent agent oversees the sequenced deployment of data-driven model to ensure that the model meets the constraints. An example of intelligent agent is one that checks if water saturation stays less than 100%. More advanced intelligent agents are included in TDM to pinpoint inconsistencies in history data and to exclude them from the modeling process. This innovative approach mitigates the risk of introducing bias by erroneous data to TDM development.
Constructing a TDM is usually time-efficient and it generally takes less than 6 months to have a full field model with outcomes. The modeling steps are as follows: (1) Data gathering and preparation: involves review and QC of all the data and identifying/excluding wells to be used for blind testing the model. (2) Model building. (3) Model training and history matching: involves performing blind test using the wells excluded in the gathering stage, by defining a suitable algorithm. (4) Model prediction: involves prediction of reservoir and well performance and conducting sensitivity analyses.
The subject reservoir is a low permeability carbonate reservoir characterized by lateral and vertical heterogeneity. More than 8 years of development and production/injection data and well test and log data (SCAL, PVT, MDT) of more than 37 wells were used to construct a top-down model for this reservoir. The well trajectory data, well logs, seismic data, production and injection history of 8 years, reservoir pressure test data, choke opening and WHP history, time-based water saturation, completion schedule and operational constraints were used as inputs for constructing the TDM.
It is common in the reservoir modeling process to use the entire production data to do history matching in numerical reservoir simulation. Top-down modeling only uses part of the data for history matching and the rest to test the prediction capability of the reservoir model. In this work, the production data of about 96 months from 2008 to 2016 were used, of which about 10-15% of the data was used to validate the TDM model. To be specific, the data from late 2008 to late 2015 were used to build the TDM model and do history matching, and the data from late 2015 to 2016 were used to blind test the correctness of the prediction by the TDM. Unlike the history matching process in the numerical reservoir simulation that concentrates on the modification of reservoir characteristics to accomplish its objective, in the Top-Down Modeling, the reservoir characteristics are assumed reasonably accurate (TDM is fact-based). In the Top-Down Model history matching, the functional relationships between reservoir characteristics, operational constraints, and production history are modified to accomplish the objective. Once the history match is accomplished, uncertainties associated with the reservoir characteristics can be analyzed and quantified by a Monte-Carlo simulation. For this work, the data-driven prediction models were built by using parameters such as well location, reservoir characteristic parameters, and operational constraints.
1.2 History matching
Any reservoir model either developed in numerical simulator or by TDM process is non-unique. One approach to mitigate this issue is to make sure that the developed reservoir model is able to replicate history data with a good accuracy. Thus, history matching is a necessary step for numerical reservoir modeling and also for TDM. A history matched reservoir model can be used to forecast reservoir behavior under new operational conditions such as variations in water injection rate and choke opening. But achieving a history match does not guarantee that the reservoir model can make accurate prediction. Introducing a bias in history matching could result in a good history match but less accurate prediction of the model. Numerical history matching can be achieved by tweaking global static (geologic model) parameters such as porosity, permeability, and initial water saturation … etc. Furthermore, local grid refinement (LGR) is usually employed to achieve a history matching for each well. In TDM, blind testing is used in time and space by applying TDM to well datasets that are not used in TDM training phase. Unlike numerical simulation, TDM is generally a global simulation in which static parameters (permeability, porosity, etc.) at well level aren’t adjusted to achieve a history match. TDM history matching can be achieved by two approaches: changing data-driven hyper-parameters such as number of hidden layers, hidden neurons, activation functions, learning rate, momentum, or changing number/or selection of input parameters. In TDM, the influences of wells adjacent to other wells (producers/injectors) are considered.
The TDM designed in this work has 5 inter-connected data-driven models. The output of one model is the input for the next model. The data-driven models of the TDM are trained and tested on available data and then applied to each well. The TDM starts with oil rate model that has pressure, saturation, water production, gas production, and oil production of (t-1) time step as inputs. Then, the predicted oil rate at time step (t) is used as an input for the water and gas rate models. Reservoir pressure model has (t-1) attributes of its subsequent models. Thus, each model can have attributes at time step (t) from its previous models and attributes at time step (t-1) from its subsequent models.
Fig. 1 shows the results of history matching for oil, gas, and water production rate of the entire reservoir. The history matched model replicates the history data with acceptable accuracy.
Fig. 1.
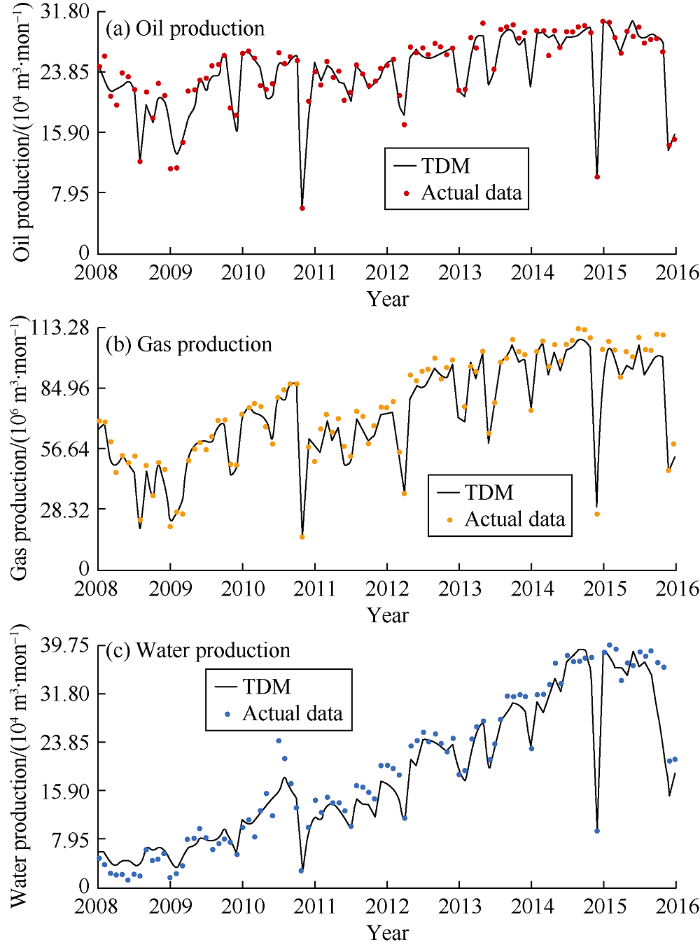
Fig. 1.
Comparison of oil, gas and water production rates from TDM history matching and actual oil, gas and water production rate.
1.3. Model validation
The TDM was blind tested by the part of the data not used in building the TDM. The results show that the TDM model has good capability when dealing with new data. Fig. 2 shows a well that was not used in training the model. The TDM results of this well match with the history data with a high accuracy implying that the model is spatially validated..
Fig. 2.
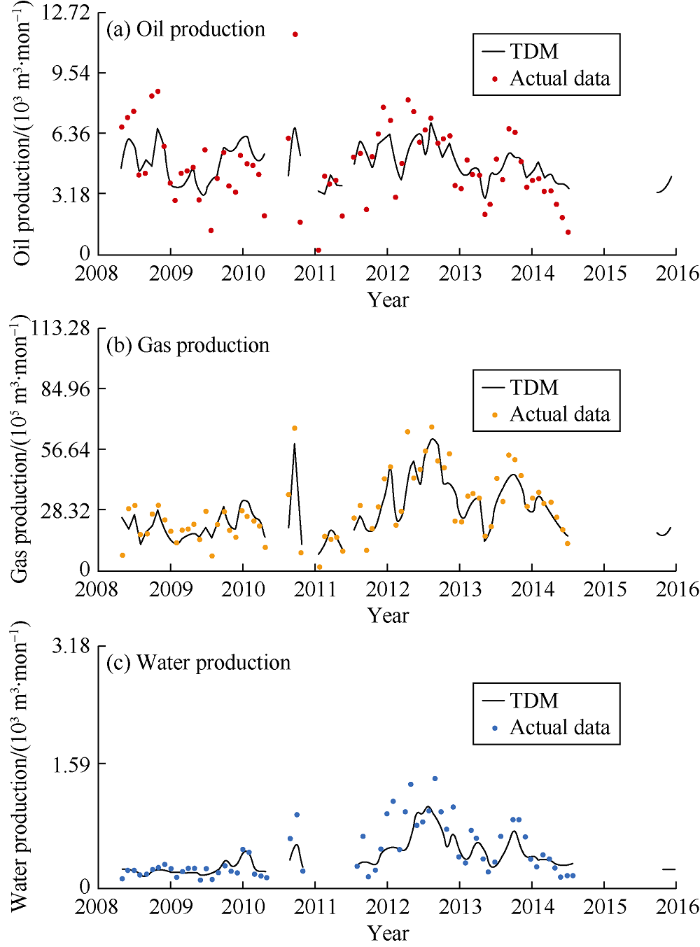
Fig. 2.
Matching results of a blind test well by the TDM model.
Moreover, the production data of the last two years not used in the development of TDM were used to blind test the TDM in time. The predicted production rates and pressures were validated by the actual production history, multiphase tested flowrates and measured pressure buildups (PBUs) and pressure fall-offs (PFOs). Due to the limited number of pressure well tests, the TDM pressure prediction error was not computed beyond the available pressure data. Fig. 3a shows the average MSE for each of the predicted parameters for all wells in the blind test period, and Fig. 3b shows the average error (x) of all predicted parameters of each well. It can be seen that 38% of the wells have a prediction error of less than 10% in two years. The increase in error with time can be attributed to the error in predicted gas and water rates. It is noteworthy that measured water and gas production rates at the field are less accurate than oil production rate, so the accuracy of predicted water and gas rates by TDM will be impaired. Fig. 4 shows the cross-plots of the predicted values by TDM. It is found from a comprehensive study that the optimal prediction window for this field case is 3 months, within 3 months, the prediction error is the lowest and the number of wells accurately predicted are most.
Fig. 3.
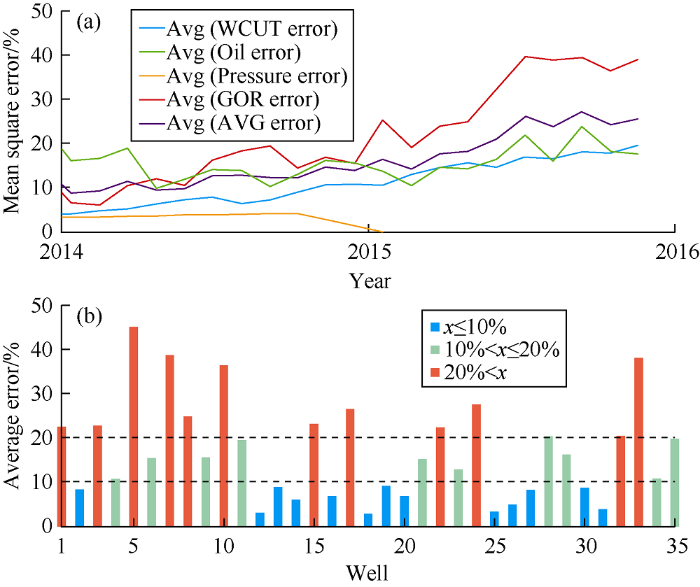
Fig. 3.
a) MSEs of all predicted parameters of the reservoir in the blind test period. b) Average MSE of all predicted parameters of each well.
Fig. 4.
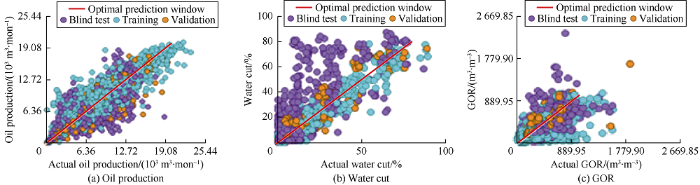
Fig. 4.
Comparison of data predicted by TDM and actual data.
During the first three months of the blind test, it can be seen that the predicted results of the model for 47% of the wells are accurate, with an error of less than 5%, those for 21.9% of the wells have errors between 5% and 10%, and those for 15.6% of the wells each have errors between 10% and 20% and over 20%. It can be seen from Fig. 5 that the average MSE of the majority of wells in the first three months of prediction is very low, indicating the model can make accurate predictions in shorter periods. Wells with higher MSE are the wells with less historical data, mostly wells put into production recently or wells with lower data quality. Fig. 6 shows the TDM predictions of a well which has an error of less than 5% in the two-year blind test.
Fig. 5.
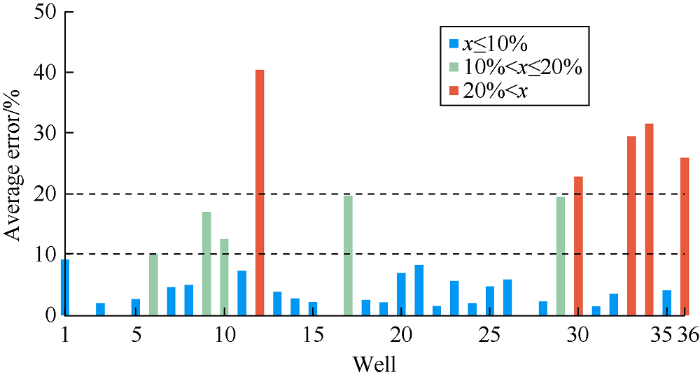
Fig. 5.
Average error of wells in the first three months of blind test.
Fig. 6.
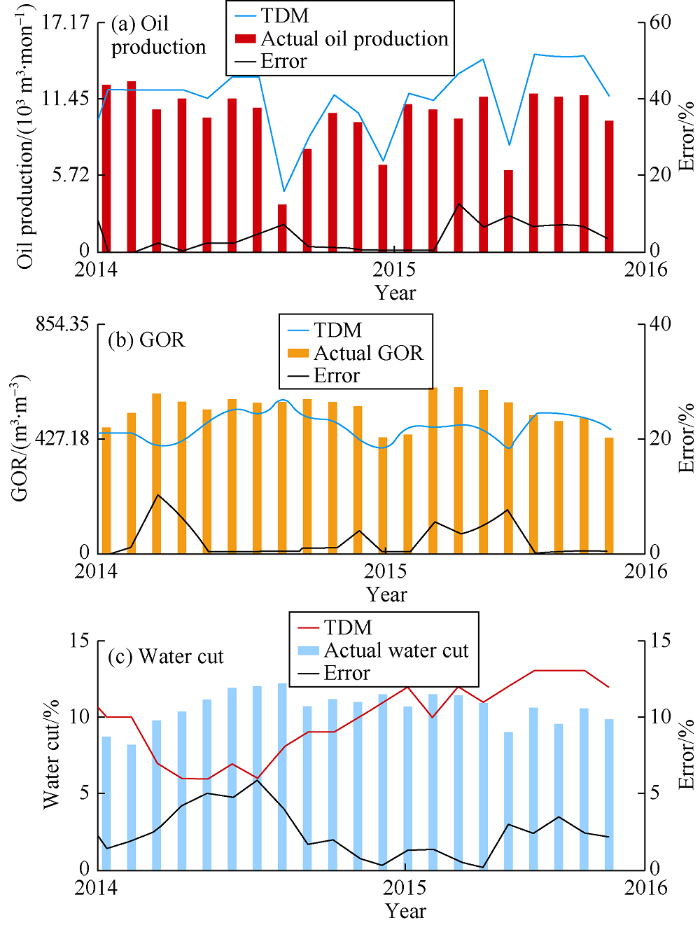
Fig. 6.
Oil production rate, GOR, water cut of a well predicted by TDM and their errors.
2. Application of the model
2.1. Production forecasting
The history matched and validated model is used to forecast reservoir performance, the choke size, WHP, and other parameters. The injection rates of WAG were set as the average (water-gas ratio of 0.65) of the last 6 months of the injection history data. The WAG alternating period was set at 6 months based on the development plan of the field. Fig. 7 shows the predicted results of a well under the above operational conditions. It can be seen that the oil production declines and water production increases with time. The forecasted period of the model is taken to plan and manage the well and reservoir performance. When new data is obtained, it is compared with the predicted data from the model to ensure accuracy of the model and used to update the model. This capability of the TDM model provides a fast and efficient way to evaluate the injection effectiveness and design future injection rate to maximize oil production.
Fig. 7.
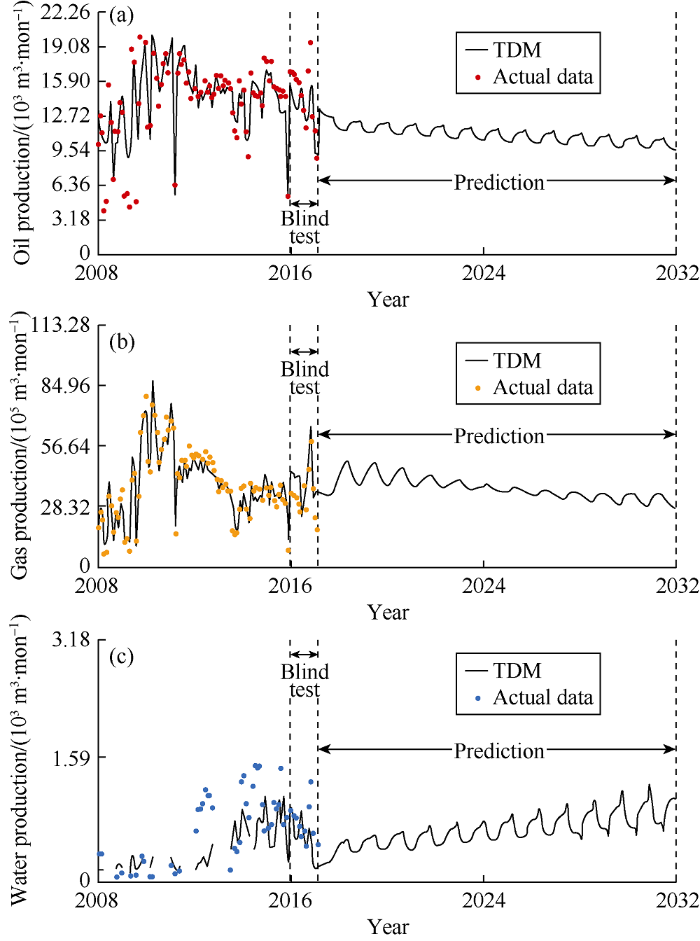
Fig. 7.
Oil, gas and water production rates predicted by TDM.
2.2. Sensitivity analysis
We used history matched model to evaluate the injection efficiency and also predict reservoir performance under various WAG scenarios. Firstly, we evaluated the injection efficiency by assuming the history data as benchmark (100% injection) and then decreased the injection rate by 25% each step to predict the reservoir behavior at the injection rate of 75%, 50%, 25% and 0% of the initial injection rate. The difference between oil production from 100% injection case and no-injection case can the development effect during WAG in this field. Fig. 8a shows that from the 36th month to 48th month of production, a lower water injection rate would result in better oil production increment. Fig. 8b shows that water injection is effective in this field and has resulted in remarkable oil production increment.
Fig. 8.
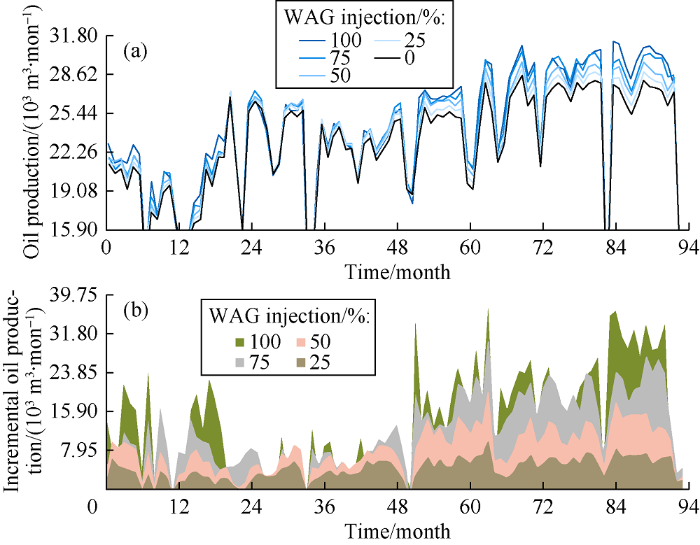
Fig. 8.
The effect of the WAG injection rate on oil production (a) and the impact of injection rate on oil increment (b).
In addition to sensitivity analysis of WAG duration, the impact of the injected fluid volume on oil production was also examined. We designed several injection scenarios by varying water and gas injection rates in WAG well (Fig. 9). The results show that a 3 months WAG injection at the default rate (average of last 6 months of history) would result in higher oil production than 6 months WAG injection. A 3 months WAG injection also is associated with less gas and water production than a 6 months WAG scenario. Fig. 9 can only show the effects of different water injection schemes, but can’t reflect the effect of injection volume.
Fig. 9.
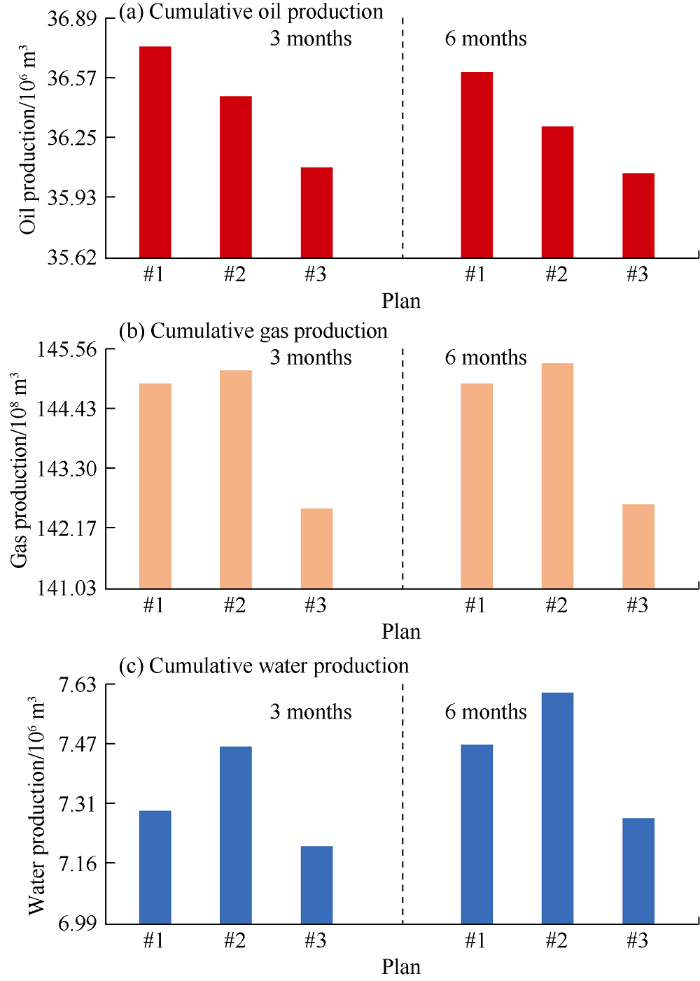
Fig. 9.
Cumulative oil production in different injection scenarios predicted by TDM ( #1—the volume ratio of injected water to gas is 1:1; #2—the volume ratio of injected water to gas is 1.0:0.5; #3—the volume ratio of injected water to gas is 0.5:1.0).
2.3. Optimization of infill well location.
Well trajectory is an input to all TDM levels. This makes it easier to assess the effect of well location on oil production. We placed new wells in the model first and then optimized the well location through iteration by TDM. Constraints such as minimum distance to offset injectors, GOR, and WC were applied. Fig. 10 shows the oil production rate, GOR and water cut of a well that is optimized in location. Executing this task in a traditional numerical simulator requires immense calcula-tions, while TDM provides a fast solution for infill location optimization. In addition, as the vertical depth of the well is an input to the TDM model, it can also be optimized. Fig. 11 shows the sensitivity of the optimized infill well location to vertical depth, which indicates that more oil can be produced by a shallower well.
Fig. 10.
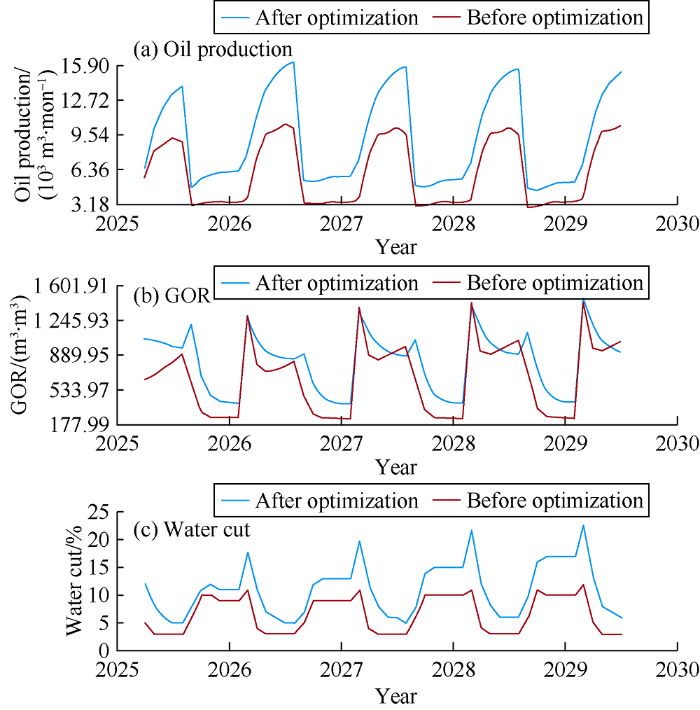
Fig. 10.
The effect of optimized well location on oil production rate, GOR and water cut.
Fig. 11.
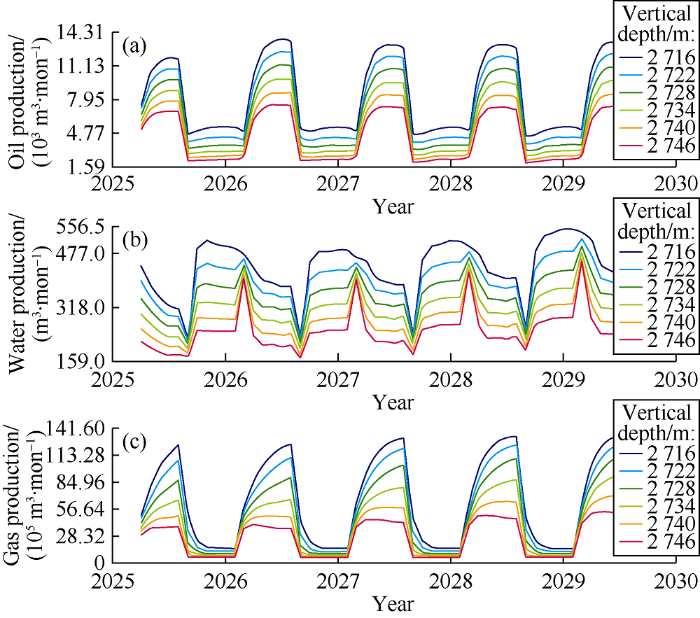
Fig. 11.
The effect of the vertical depth on oil, water and gas production rates of a well.
3. Conclusions
A TDM for a carbonate reservoir in the Middle East was developed. It includes 5 interconnected data-driven artificial neutral network models, each neutral network build a model for a key dynamic parameter and the output of a model is the input of the next model. The TDM has good history matching effect, which was validated in time and space. When applied to new data, the TDM has the capability to predict the reservoir performance 3 months ahead with acceptable accuracy. The predicted results by the TDM show that under given conditions, the oil production rate declines and water production increases; higher volumes of injected gas and water won’t necessarily have a positive effect on oil producers; a lower injection volume in a period of the injection instead will result in higher oil production; and for different injection schemes, the scheme with a 3-month injection period has higher oil production rate that that with a 6-month injection period. The TDM provides a fast and reliable means for optimizing WAG parameters, and can also optimize location of infill wells.
Acknowledgements
The authors would like to acknowledge and thank ADNOC and ADNOC Onshore Management for giving permission to publish this paper and their support for this project.
Reference
A novel approach to assist history matching using artificial intelligence
Reservoir simulation and modeling based on artificial intelligence and data mining (AI&DM)
Top- down, intelligent reservoir modelling of oil and gas producing shale reservoirs: Case studies
Application of using fuzzy logic as an artificial intelligence technique in the screening criteria of the EOR technologies
Selection and evaluation of enhanced oil recovery method using artificial neural network
Application of artificial intelligence methods in drilling system design and operations: A review of the state of the art
Intelligent time-successive production modeling
Field development strategies for Bakken shale formation
Modeling, history matching, forecasting and analysis of shale reservoirs performance using artificial intelligence
Neural networks and learning machines

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}