


Introduction
The prediction of oilfield development indicators is the basis for evaluation of oilfield development effects, preparation of oilfield development plans, and design and adjustment of oilfield development schemes. Only by scientifically and reliably predicting oilfield development indicators can we match the arrangement of stimulation measures and workloads rationally to ensure the realization of goals.
The waterflooding characteristic curves are not suitable for describing the production decline of oilfield at an ultra-high water cut stage (water cut more than 90%). The curve will be upward and have a large prediction error[1,2,3]. Some of the waterflooding characteristic curves are modified to fit the actual production data in the ultra-high water cut stage, but the obtained curves are mostly nonlinear ones, which are not easy to use and have larger errors in predicted oilfield production by extrapolation. In addition, the geological conditions of the oilfield are complex and the formation physical properties are varied at the ultra-high water cut stage. Conventional reservoir engineering methods generally can only make smooth predictions by considering a few influencing factors[4,5]. The reservoir numerical simulation method takes a lot of time and high cost. It is necessary to find a development indicator prediction method that can improve prediction efficiency and accuracy.
In recent years, with the extensive application of artificial intelligence in the fields of science and engineering, digital transformation, big data, and artificial intelligence have become hot spots in the oil and gas industry[6,7,8,9,10,11,12]. Reports of artificial intelligence applications frequently appear in academic journals of the upstream field of the petroleum industry[13,14,15,16,17,18]. Support Vector Machine (SVM), Autoregressive (AR) and Artificial Neural Network (ANN) methods are used to predict geological features[19], lithology identification[20] and main influencing factors analysis of oil well production[21,22,23], etc. The Fully Connected Neural Network (FCNN) is the main stream method for predicting oil well production[24,25,26,27,28]. However, FCNN cannot save and use the information at the previous time and predict time series data, so some combined models have been developed to predict oil well production[29,30]. In order to generate production time series data of the oilfield at a high water cut stage, a more rational choice is to use Recurrent Neural Network (RNN). Each neural unit of RNN has a self-loop structure that can re-use the previous unit. This loop structure allows the previous information to be stored and used later. Since the information can flow freely in the recurrent neural network, the production prediction based on this method takes the time factor into consideration, and thus is more in line with the actual production.
Long Short-Term Memory (LSTM)[31], one of deep learning algorithms, is applied to predict oilfield production at the ultra-high water cut stage in this study. It is also applicable to predict oilfield and well production at other stages[32,33]. This network introduces a gate structure in each self-circulation cell to further imitate the biological neuron information transmission mode, by which longer-term sequence information can be stored without any additional module. With this advantage, this neural network has drawn great attention in artificial intelligence and deep learning fields, and has been widely used in fields such as natural language processing[34], speech recognition[35], and machine translation[36]. In addition, LSTM is also used in hydrology, finance and other fields to deal with problems involving time series data[37,38].
The purpose of this study is to predict the oilfield production at an ultra-high water cut stage by using LSTM based on the historical oilfield production data. First, the theoretical basis of LSTM and the network structure are introduced. Secondly, the application effect of LSTM in the production prediction is analyzed, and the predicted production is compared with the predicted production by the traditional waterflooding characteristic curves and FCNN model.
1. Principles and methodology
1.1. Long short-term memory neural network
Unlike regression prediction, time series prediction has a complicated sequence dependence in time. FCNN cannot predict the result in the current time based on the prediction of the previous time and cannot analyze the correlation between successive data points in the sequence. The structure of the RNN enables the information in the previous steps to be saved to affect the calculation of the subsequent steps. However, if the distance between the location of previous relevant information and the current step is very far, the memory module in the model (single tanh layer or sigmoid layer) cannot effectively store historical information for a long time, and is prone to problems such as gradient disappearance or gradient explosion with the continuous feeding of data[39]. LSTM is a special RNN, which has a memory module modified from that of the traditional RNN. By improving the design of the gate structure and the state of memory unit, LSTM can effectively update and transfer the long-distance useful information in the time series and store the long distance information in the hidden layer. The recurrent network of hidden layer in LSTM includes a forget gate, an input gate, an output gate and one tanh layer. The processor cell selectively saves the useful information from the previous steps through the entire LSTM. The gates in the interaction layer can add, delete and update the information in the processor cell according to the hidden state of the previous step and the input of the current step, and the updated processor state and hidden state are passed down[27]. The LSTM model supports end-to-end forecasting, and can realize prediction of single indicator with single-factor or multiple factors, and prediction of multiple indicators with multiple factors.
1.2. Feature selection
Uncorrelated variables may negatively affect the prediction accuracy of the machine learning model. Feature selection can eliminate irrelevant variables, improve model accuracy, and avoid the problem of overfitting.
Recursive feature elimination[40] algorithm is one of the feature selection methods. Its main idea is to use a base model (support vector machine model in this study) for multiple iterations of training. The model is trained based on all the features, and each feature is scored according to the training results. The scoring rules for each feature are shown in equation (1). The feature with the lowest score, that is, the least important feature is eliminated. The next round of training is executed using the remaining features until the last feature remains. The order of feature elimination is the importance ranking of the features. The feature eliminated first is the least important, and the feature eliminated last is the most important.
2. Data preprocessing and model training
An oilfield production prediction model was established using the production data of an oilfield in China. The oilfield is a medium-high permeability sandstone oilfield developed by waterflooding, and it entered into an ultra-high water cut stage in 2005. At present, it has 14×103 oil wells, an annual production of more than 8 million tons of oil and a water cut of greater than 95%. The production data from January 2001 to December 2018 of the oilfield was used to carry out model verification experiments. According to the characteristics of waterflooding development in the sandstone oilfield and history of the oilfield development and production, the factors influencing production were selected, including the number of new wells, the production of new wells, the number of oil wells put into production last year, the oil production contribution of wells put into production last year, the number of oil wells put into production in last 2 years, the oil production contribution of wells put into production in last 2 years, ... , the number of oil wells put into production in last 9 years, the oil production contribution of wells put into production in last 9 years, the number of oil wells put into production in last 10 years and before, the oil production contribution of wells put into production in last 10 years and before, the number of injection wells, monthly injection volume, water cut, production days, remaining recoverable reserves, recoverable reserves used in the new area, newly added recoverable reserves in the old area, the number of stimulation wells, oil increment of stimulation and crude oil prices, 32 features in total. It should be noted that taking the year of 2018 as an example, the last year is 2017, 2 years ago is 2016, and so on. The main purpose of the experiment is to: (1) evaluate the LSTM's ability to predict future production based on production influencing factors and historical production data; (2) compare the prediction results of LSTM, traditional waterflooding curve method and FCNN.
2.1. Analysis of influencing factors
If all 32 influencing factors are used, all the data must be of high quality, and factors with low correlation will cause interference to the accuracy of the model. If only the main control factors are used, the model will increase in flexibility, decrease in complexity and improve in accuracy. Hence, the support vector machine-based recursive feature elimination method was used in this study to select features, and the influencing factors were ranked according to importance. After cross-validation, the optimal number of features is 17, so the top 17 influencing factors were selected, namely the number of production days, the oil production contribution of wells put into production in last 10 years and before, the oil production contribution of wells put into production last year, the oil production contribution of wells put into production in 9 years, the oil production contribution of wells put into production in last 7 years, the oil production contribution of wells put into production in 6 years, the oil production contribution of wells put into production in 4 years, the oil production contribution of wells put into production in 3 years, the oil production contribution of wells put into production in 8 years, the oil production contribution of wells put into production in last 5 years, the oil production contribution of wells put into production in last 2 years, the number of new oil wells put into production in last 10 years and before, the production contribution of wells put into production in current year, the number of stimulation wells, oil increment of stimulation, the number of produced wells in current year, monthly injection volume.
2.2. Data standardization
In order to improve the prediction accuracy of the model and eliminate the influence of different dimensions of different indicators, it is necessary to preprocess the input and output data. Since the data are relatively stable, there are no extreme maximum and minimum values. In this study, the normalized processing method was used to map the data to the [0, 1] range. The linear transformation equation is as follows:
2.3. Construction of sample set
2.3.1. Construction of feature vector
Assuming that Xt is the feature vector of production influencing factors at time t, the goal is to predict the oilfield production in the next N months. Each feature vector contains 17 features, F1-F17. F1-F9 are the oil production contributions of wells put into production for the last 1-9 years, F10 is the oil production contribution of wells put into production for the last 10 years and before, F11 is the number of oil wells put into production for the last 10 years and before, F12 is the production contribution of wells put into production in current year, F13 is oil increment from stimulation, F14 is production days, F15 is the number of produced wells in current year, F16 is the monthly injection volume, and F17 is the number of stimulation wells. Features F1-F13 use data at time t. Features F14-F17 use the data at time t+N. If there is actual production data available, the production data is used, otherwise the planning data is used. In other words, the time of the last 4 features lags behind the time of the first 13 features by N months.
2.3.2. Construction of time series data
The unique structure of LSTM requires the input data is series of feature vectors. The series of feature vectors is composed of continuous M features, and M is the step size of time series. Therfore, before training, the input series of LSTM needs to be constructed. Assuming that Xt is the feature vector at time t, the input sequence form construction is {Xt–M+1, Xt–M+2, …, Xt}. The first sequence is {X1, X2, …, XM}, the second sequence is {X2, X3, …, XM+1}, and so on.
2.3.3. Construction of learning samples
The function of predicting multiple indicators with multiple factors in the LSTM model was applied, that is, the oilfield productions of several months in history were used to predict the oilfield productions of several months in the future. The samples consisted of an input time series and an output time series. Suppose the production time is T, that is, the production data of T months is observed, the time step is M, the predicted production lags N months, Yt is the monthly oil production at the moment of t. Then the input time series include SI1={X1, X2, …, XM}, SI2={X2, X3, …, XM+1}, …, SIZ={XZ, XZ+1, …, XZ+M–1}; and the output time series include SO1= {YM+1, YM+2, …, YM+N}, SO2={YM+2, YM+3, …, YM+N+1}, …, SOZ= {YM+Z, YM+Z+1, …, YM+Z+N–1}. The number of supervised learning samples is Z, then Z= T-N-M+1.The input sample required by the model is a three-dimensional tensor in the form of (Z, M, F), where F is the dimension of the feature vector. In the input time series, the input data is divided into A and B two parts: Part A contains the features F1-F13, which represent the actual production data from the first month to the T-N month; Part B contains features F14-F17, which represent the planned data from month T-N+1 to month T.
2.3.4. Data set splitting
In this study, 216 months of production data from January 2001 to December 2018 were selected as the experimental data. The time lag and serialization methods mentioned above was followed to assemble the sample data sets fed into the LSTM. The data from January 2001 to December 2016 was taken as the training set, the data from January 2017 to December 2017 was taken as the validation set, and the data from January 2018 to December 2018 was used as the test set.
2.4. Evaluation indexes
To evaluate the accuracy of predicted production by LSTM model, Correlation coefficient and Mean Absolute Percentage Error (MAPE) were used as two evaluation indexes.
2.5. Model training and tuning
Tensorflow platform was used as the deep learning platform, Python 3.3 was used to code the experimental program, and some third-party libraries were used, such as Sklearn and Numpy, and Keras was used to build the network structure.
2.5.1. Model training
The LSTM parameters were randomly initialized. The number of neural network layers was set as 1. The number of timesteps was 12 months. The number of neurons was 55, the number of training epochs was 60, and batchsize was 3. Then the training data was fed to train model, and the test data was used to validate the model.
Take the prediction of the oilfield production in the 12 months of 2018 as an example. The input data is serial data with time step size of 12. Part A is the actual production data from January 2017 to December 2017, and part B is the planned data from January 2018 to December 2018. The output data is the monthly oil production data series from January 2018 to December 2018. The prediction results with the model have a correlation coefficient of 0.83 and mean absolute percentage error of 25%.
2.5.2. Automatic tuning
When the parameters of the neural network are randomly initialized, the prediction results of the model are not necessarily accurate. As there are many parameters in the neural network model, and each parameter has a wide value range, the method of setting the parameter range manually and the computer automatically searching for the optimal solution was adopted to train the model. Firstly, the overfitting model was developed by manual attempts, such as adding more hidden layers, setting more neurons in each layer. The variations of training error and validation error were monitored to determine the parameter range by looking for the position on the validation data set where the performance began to decline (overfitting).Take the number of network layers and time series step size as an example, as shown in Fig. 1, when the number of network layers is 2, the predicted value has a correlation coefficient of 0.94 with the real value, and a mean absolute percentage error of 2%. When the number of network layers increases further, overfitting occurs, and the predicted result has a large deviation from the real value. Therefore, the range of network layers is set as [1, 2]. As shown in Fig. 2, when the time series step size is less than 13 months, the correlation coefficient is greater than 0.80 and the mean absolute percentage error is less than 20%, so the range of time step size is set as [1, 12].
Fig. 1.
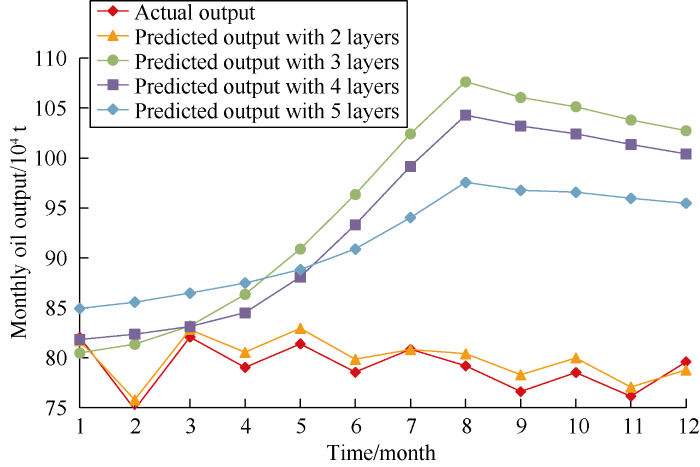
Fig. 1.
Comparison of predicted production with neural networks of different layers with actual production.
Fig. 2.
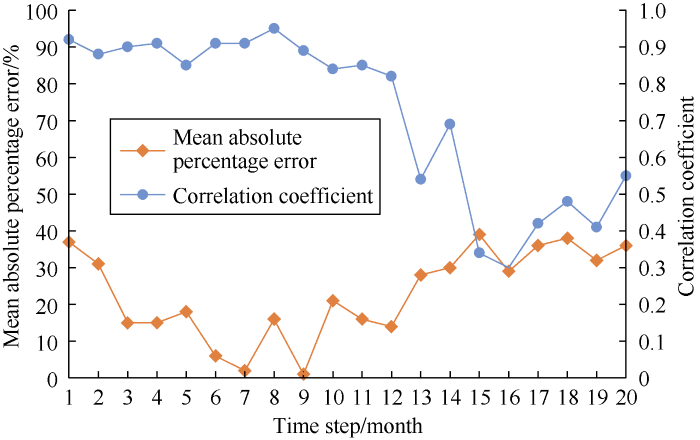
Fig. 2.
Correlation coefficient and mean absolute percentage error at different time series step sizes.
After determining the ranges of all parameters, the computer automatic tuning method was used to find the optimal parameter combination. The parameters after automatic tuning included the number of network layers, time step size, the number of neurons, the number of training epoch and batch size. The step size of each parameter was set according to its determined range and combined with oilfield development and production experience. The parameters and values are shown in Table 1.
Table 1 Parameter combination of neural network.
| Parameter | Value |
|---|---|
| Layers | 1, 2 |
| Time step | 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 |
| Neuros | 5, 15, 25, 35, 45, 55, 65, 75, 85, 95, 105 |
| Epochs | 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150 |
| Batch size | 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 |
Mean Square Error (MSE) was used as the loss function of LSTM.
The Optimizer "adam" was adopted to calculate the adaptive learning rate of each parameter in the neural network. Overfitting was prevented by Dropout (the temporary removal of neurons from the network at a proportion of 30%).
There were 34 848 parameter combinations. Distributed computing technology was used to generate corresponding model files and predict results. After all parameters were trained, the model with high correlation coefficient and small mean absolute percentage error was selected as the optimal model.
3. Results and discussions
3.1. Results
The optimal model was used to predict the oilfield production in 2018. The predicted production has a correlation coefficient of 0.93 with the actual production, and the average absolute percentage error of 1% (Table 2). The optimal parameter combination of LSTM was the number of hidden layers of 2, the number of neurons in hidden layers of 55 and 25, and the time step size of 9 months, that is, the data of the past 9 months was used to predict the oilfield production of the next month, the batch size of 2, that is, the network parameters were updated once every 2 samples, and the number of epochs of 60.
Table 2 Comparison of predicted results with water drive characteristic curve, FCNN and LSTM.
| Model | Feature dimensions | Correlation coefficient | Mean absolute percentage error/% |
|---|---|---|---|
| Water drive curve | 2 | 0.94 | 8 |
| FCNN | 32 | 0.20 | 26 |
| 17 | 0.45 | 7 | |
| LSTM with 1 layer | 32 | 0.74 | 15 |
| 17 | 0.83 | 5 | |
| LSTM with 2 layers | 32 | 0.90 | 4 |
| 17 | 0.93 | 1 |
Based on the prediction results on the test set (Fig. 3), the prediction results of the LSTM model show basically the same trend and closer values with the actual production data, proving the LSTM model can make more accurate prediction than the traditional water drive curve and FCNN model. The experimental results show that the LSTM model can be used to predict the time series of oil and gas production.
Fig. 3.
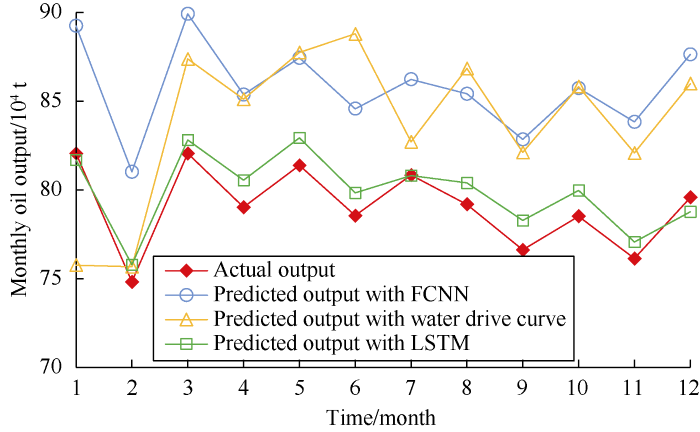
Fig. 3.
Comparison of prediction results from water drive curve, FCNN and LSTM.
The LSTM model was applied to predict the monthly oil production of two other oilfields in 2018 (Table 3), the prediction results are quite accurate, proving the universality of the method presented in this paper.
Table 3 Predicted production of two other oilfields by LSTM model.
| Time | Monthly oil output of oilfield 1 | Monthly oil output of oilfield 2 | ||||
|---|---|---|---|---|---|---|
| Actual output/t | Predicted output/t | Relative error/% | Actual output/t | Predicted output/t | Relative error/% | |
| January 2018 | 359 499 | 348 874 | 2.96 | 7964 | 7961 | 0.04 |
| February 2018 | 320 816 | 321 998 | 0.37 | 7137 | 7821 | 9.58 |
| March 2018 | 345 256 | 344 530 | 0.21 | 7529 | 7893 | 4.83 |
| April 2018 | 331 233 | 335 417 | 1.26 | 7462 | 7868 | 5.44 |
| May 2018 | 342 588 | 339 255 | 0.97 | 8173 | 7965 | 2.54 |
| June 2018 | 338 639 | 334 328 | 1.27 | 8020 | 7840 | 2.24 |
| July 2018 | 348 521 | 340 717 | 2.24 | 8000 | 7876 | 1.55 |
| August 2018 | 346 023 | 341 975 | 1.17 | 7968 | 7779 | 2.37 |
| September 2018 | 330 353 | 334 579 | 1.28 | 7315 | 7795 | 6.56 |
| October 2018 | 342 760 | 340 823 | 0.57 | 6988 | 7918 | 13.31 |
| November 2018 | 329 982 | 333 913 | 1.19 | 6928 | 7712 | 11.32 |
| December 2018 | 338 437 | 336 907 | 0.45 | 7481 | 7787 | 4.09 |
3.2. Discussions
LSTM, one of machine learning algorithms, was applied to the production prediction of oilfield at an ultra-high water cut stage in this work. LSTM can effectively establish patterns of production series with long-term correlation in time, and predict oilfield production based on these patterns.
The prediction accuracy of the model is affected by the number of factors used in the model training process. The LSTM model takes into account both the relationships between the production indicators and the influencing factors, and the variation trends of production indicators themselves, so it has higher prediction accuracy and correlation. FCNN only considers the relationships between the production indicators and the influencing factors, so its predictions are higher than the actual values. The water drive characteristic curve model only considers the variation trend of production itself, so its prediction result is higher than the actual value. Feature engineering also has an important impact on the model prediction accuracy. For the same model structure, the prediction results after performing feature engineering operations are much better than those without feature engineering operations. Based on the analysis of feature engineering, the oil production of wells put into production every year, the number of production days, the number of new production wells, the number of stimulation wells, oil increment of stimulation, and monthly injection volume have a greater impact on production. According to the analysis of the prediction results, LSTM has a strong feature extraction capability for time series data. It can extract the producing profile data of the production wells over the past years, and simulate the production of wells put into production in the past years based on the historical production information stored in the neural network memory unit, equivalent to predicting production of old wells. It can mine the relationship between the number of new wells and the production of new wells and predict the production of new wells; and can predict oil increment by using the number of stimulation wells and oil increment of stimulation in the past.
4. Conclusions
Based on data-driven method, the production prediction model of oilfield at an ultra-high water cut stage has been established by using LSTM. Compared with the water drive characteristic curve model, the predicted production with LSTM model shows a good agreement and small errors with the actual production. This new model can quickly predict production variations of new wells and old wells. Compared with numerical simulation model, this method does not require the establishment of a physical model and can achieve rapid prediction. Although the physical meaning is missing, it can enrich production prediction methods and support oilfield development and adjustment.
LSTM has strong nonlinear fitting and time memory capabilities, and has a strong ability to extract information from training data. It can not only consider the relationships between the production indicators and the influencing factors, but also the variation trends of the production indicators themselves. LSTM is to establish a nonlinear mapping relationship between targets and influencing factors based on historical data. To establish a production prediction model by LSTM for the ultra-high water cut stage, it is necessary to obtain production data of the ultra-high water cut stage for a certain period of time. The oilfield selected in this study has production history at ultra-high water cut stage of more than 10 years, and the production data of 4 years before the ultra-high water cut stage was used in the model training. For oilfields with short production history, the method of transfer learning based on other oilfield training models with longer period of production can be used for predictive analysis. Feature engineering can improve model accuracy. Feature selection can filter out less important factors. Data standardization can eliminate the influence of dimension. The depth of the neural network should adapt to the complex situation of the data. The range of the model parameters should be determined through monitoring the model accuracy curve. The model training efficiency can be improved by using distributed computing technology to train different model parameter combinations.
Nomenclature
ci—score of the ith feature;
F—feature vector dimension;
M—time step size, month;
N—lagging time, month;
t—time, month;
T—production time, month;
X—feature value of production indicator;
Xmax—maximum value of the production indicator;
Xmin—minimum value of the production indicator;
Xnorm—normalized value;
Xt—feature vector at time t;
Yt—monthly predicted production at time t;
Z—the total number of samples;
ωi—the weight of the ith feature of the optimal hyper plane in the support vector machine model.
Reference
Production decline analysis and characterization formula of decline rate at the ultra-high water cut stage
New water drive characteristic curves at ultra-high water cut stage
Derivation of water drive curve at high water-cut stage and its analysis of upwarding problem
Basic principle and application of modern production decline analysis
A brief review of production decline analysis methods
Shale fracturing characterization and optimization by using anisotropic acoustic interpretation, 3D fracture modeling, and supervised machine learning
Machine learning- based method for automated well-log processing and interpretation: ALUMBAUGH D, BEVC D. SEG technical program expanded abstracts 2018
Automatic channel detection using deep learning: ALUMBAUGH D, BEVC D. SEG technical program expanded abstracts 2018
Classifying geological structure elements from seismic images using deep learning: ALUMBAUGH D, BEVC D. SEG technical program expanded abstracts 2018
Tapping the value from big data analytics
Facies classification using machine learning
Geology-driven estimated-ultimate-recovery prediction with deep learning
Technology focus: Formation evaluation (August 2018)
Technology focus: Petroleum data analytics
Long short-term memory and variational autoencoder with convolutional neural networks for generating NMR T2 distributions
Geological feature prediction using image-based machine learning
Artificial neural networks to support petrographic classification of carbonate-siliciclastic rocks using well logs and textural information
DOI:10.1016/j.jappgeo.2015.03.027 URL [Cited within: 1]
Analysis of main controlling factors of shale gas horizontal well production based on grey correlation method
Analysis of production control factors and productivity prediction of horizontal wells in shale gas
Study on main control factors and production prediction of single well production of coalbed methane based on machine learning
Oil well production prediction based on improved BP neural network
Shale gas production decline prediction model based on improved BP neural network based on genetic algorithm
Application of BP neural network optimization based on genetic algorithm in crude oil production prediction: Take BED test area of Daqing Oilfield as an example
Dynamic analysis method of oil field production based on BP neural network
Research on prediction model and algorithm of oilfield development index based on artificial neural network
Oil well production prediction based on ARIMA-Kalman filter data mining model
Oilfield production prediction and application based on time series analysis method
Long short-term memory
URL PMID:9377276 [Cited within: 1]
Prediction method of oil well production based on data mining based on long-term and short-term memory network model
Prediction method of oil production in new wells based on long and short term memory neural network
Recurrent neural network based language model
Sequence to sequence learning with neural networks
A prediction model for time series based on deep recurrent neural network
Application of SDAE-LSTM model in financial time series forecasting
Learning context-free grammars: Capabilities and limitations of a recurrent neural network with an external stack memory: Proceedings of the Fourteenth Annual Conference of the Cognitive Science Society
Gene selection for cancer classification using support vector machines
DOI:10.1023/A:1012487302797 URL [Cited within: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}